Abstract
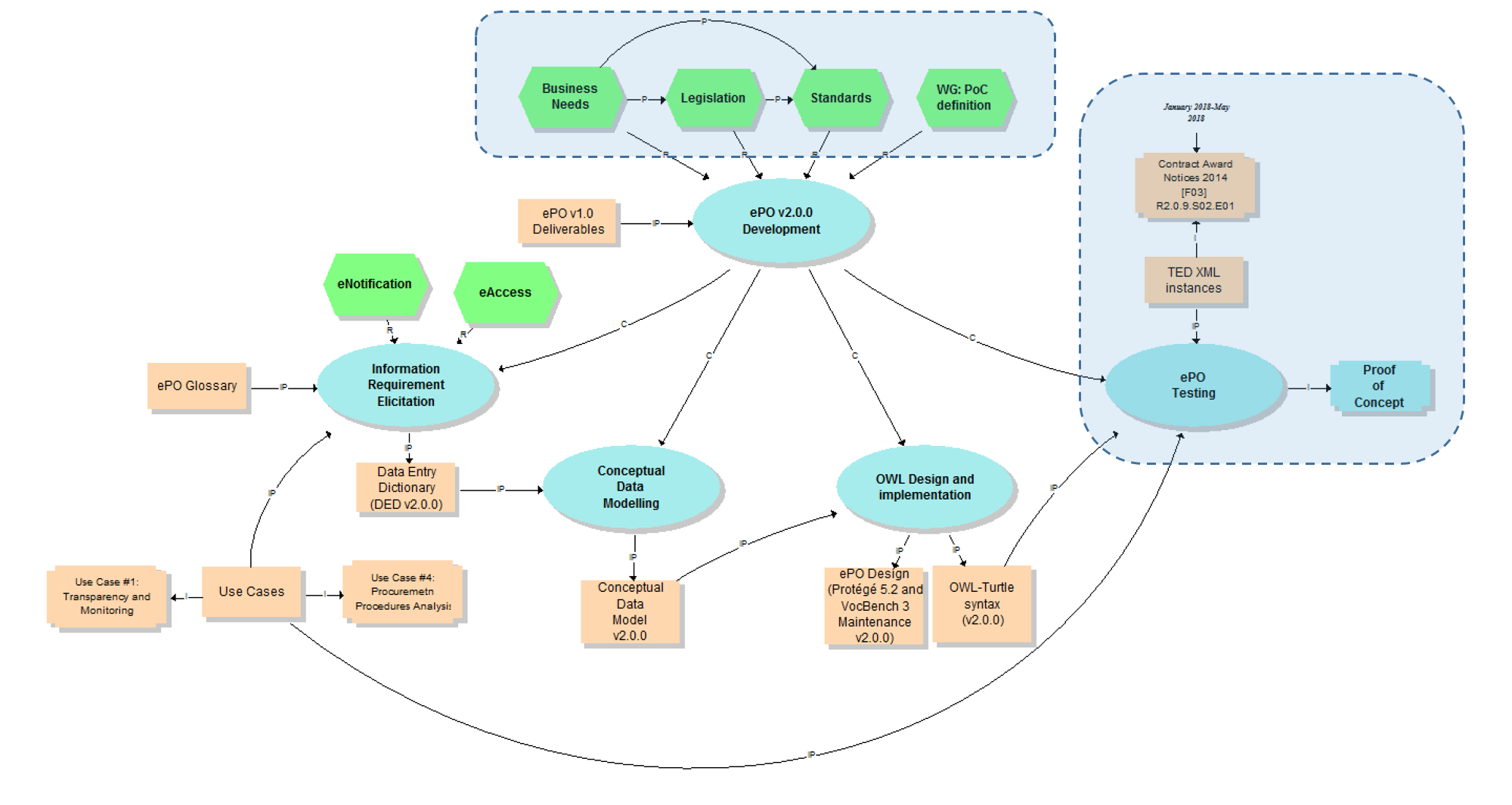
In 2016 the Publications Office of the European Union (Publications Office or OP) started a project funded by the ISA Programme to organise and support the development of a Public Procurement Ontology (ePO).
The ultimate objective of the ontology is to put forth a commonly agreed OWL ontology that will conceptualise, formally encode and make available in an open, structured and machine-readable format data about public procurement, covering it from end to end, i.e. from notification, through tendering to awarding, ordering, invoicing and payment. With this goal in mind the OP engaged a Working Group (WG) of experts with the mission of building consensus on the analysis results and deliverables developed by the OP’s teams.
By mid-2017 a version 1.00 of the Ontology was delivered and submitted to the Working group for discussion. All the materials related to this version were made public and are accessible through the ISA2 Joinup platform; including the discussions held in the Working Group (WG).
A new stage of the development, identified as ePO v2.0.0, was initiated in January 2018. The goal of this new version is to improve and extend the previous version.
This document describes the objectives, the methodological approach and the deliverables produced in this new version.
I. Context
Given the increasing importance of data standards for e-Procurement, a number of initiatives driven by the public sector, the industry and academia have been launched in the recent years. Some have grown organically, while others are the result of standardisation work. The vocabularies and the semantics that they are introducing, the phases of public procurement they are covering, and the technologies they are using vary greatly amongst themselves. These differences hamper data interoperability and their reuse.
This situation creates the need for a common representation of the knowledge about the eProcurement domain as it is understood and practiced in the European Union. For this to happen a common vocabulary, axioms and rules are needed.
This document describes the work carried out by the Publications Office and the working group to develop the "eProcurement Ontology" (henceforth referred to as the ePO).
About ePO v1.00
One fundamental document for the development of the eOP is its Project Charter. This document defines the principles, scope and the foreseen time-line and resources needed to develop the Ontology.
In this document the ultimate objective was stated as "to put forth a commonly agreed OWL Ontology that will conceptualise, formally encode and make available in an open, structured and machine-readable format data about public procurement, covering it from end to end, i.e. from notification, through tendering to awarding, ordering, invoicing and payment".
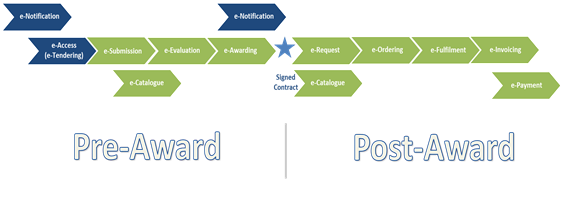
The figure below represents the eProcurement Value-Chain as commonly envisaged in Europe (source: OP).
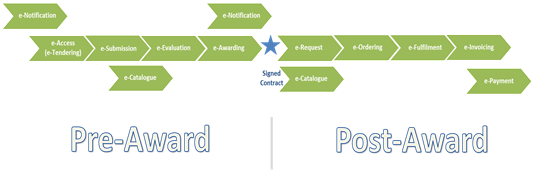
The scope of the Charter was set to cover the specification showing the conceptual model and its representation in OWL, and the deployment of the ontology and related code lists and classifications on the Metadata Registry, which is being moved to EU Vocabularies.
The original aim was to produce the final Ontology within twelve months including a public review of at least two months; and a set of three deliverables was identified as the main outcome of the project:

For the development of these objectives the OP team proposed a methodological approach based on the recommendations and good practices [1][2].
Following the work of the Working Group (WG) and the Publications Office version 1.0 of the eProcurement Ontology (ePO) was delivered in the planned period of 12 months.
ePO v.20.0. objectives
The experience of the version 1.0 proved that the goal of developing a whole ontology on eProcurement that is aligned to the EU legislation and practices was too ambitious to be completed in 12 months.
Two other relevant conclusions were drawn from that experience:
-
The concepts of the ontology needed of commonly agreed terms and definitions that directed the design and implementation;
-
The development of the ontology requires a "phased" approach based on the Use Cases defined version 1.0 on the one hand; but also focused on at least one of the processes of the eProcurement value chain, on the other hand (see figure 4 above).
Hence the proposal of second version of the ePO ontology, named ePO 2.0.0.
The main objective of the ePO v2.0.0 is to take leverage of the results produced in version 1.00 and to extend and hone the OWL Ontology. To reach these objectives the owners of the project have set the following strategic objectives:
-
Focus on one important policy area, e.g. "Transparency";
-
Extend and perfect a small set of phases of the eProcurement, if possible only one, e.g. e-Notification and e-Access.
-
While developing the selected phase, elicit and define information requirements and data elements that will be used in other phases, even if the selected phases - i.e. eNotification and eAccess-do not use them;
-
Select a rich source of information from where to extract data in order to populate and test the ontology, e.g. the TED portal for eNotification.
Scope
Hence the scope of the ePO v2.0.0 was set to the eNotification and eAccess phases of the Public eProcurement value chain, represented as blue coloured in the figure below:
Tasks in-scope
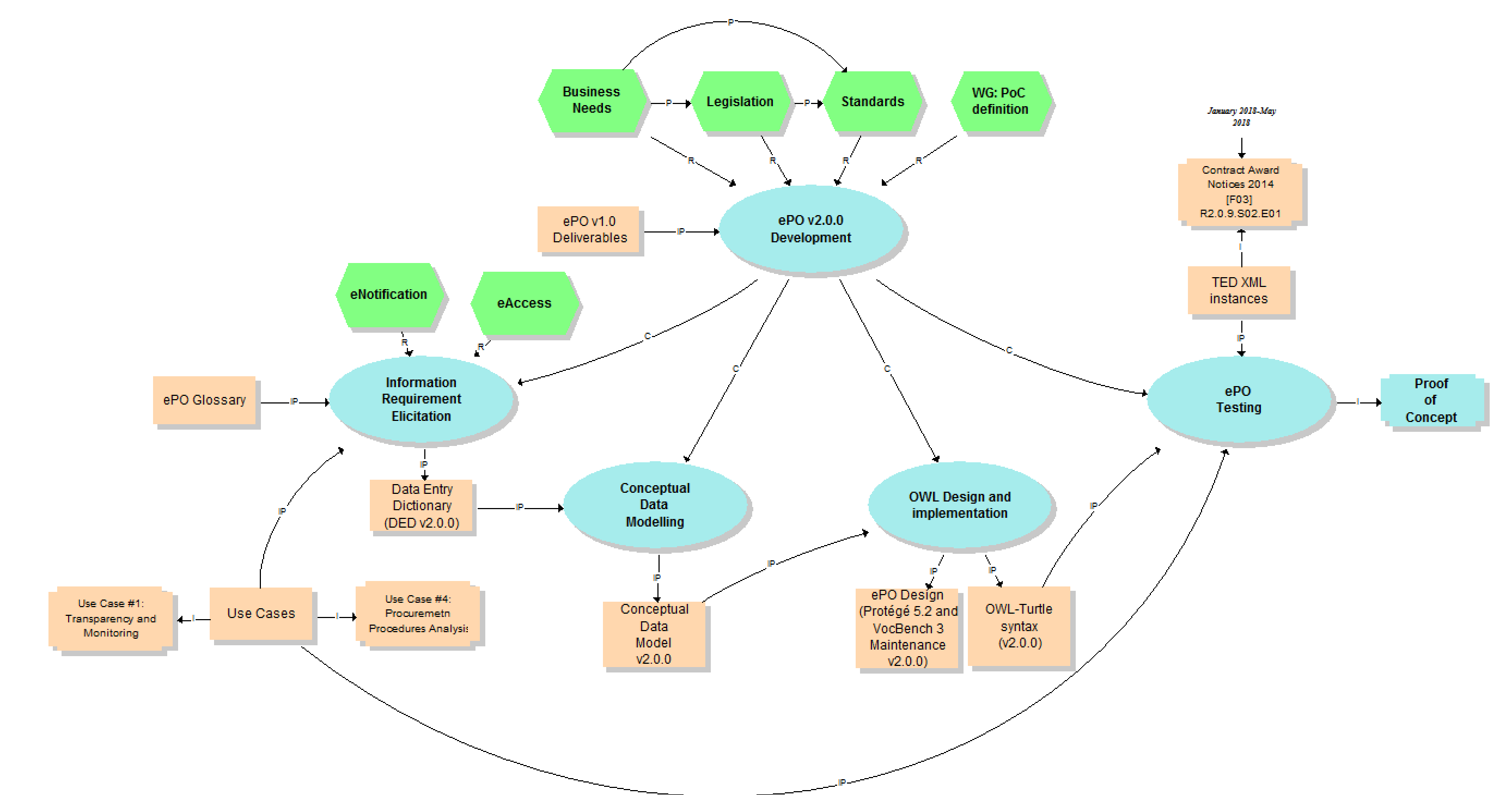
The Knowledge Map (K-Map) [3] below provides an abstract representation of the objectives, tasks, inputs and outputs in the scope of the ePO v2.0.0 (see Annex III for a summary of the MOTPLus vocabulary and syntax).
Each task (ellipses in blue) is used to organise the structure of the rest of this document into four main sections:
-
Information requirement elicitation: About the main inputs taken into consideration when identifying information requirement and artefacts used to this elicitation;
-
Conceptual Data Model: About the analysis of the information requirements - and business rules- and the drafting of a simple graphic representation of the Ontology;
-
OWL design and implementation: About the transformation of the Conceptual Data Model into a machine-readable OWL DL format that includes the vocabulary and the axioms of the ePO;
-
ePO testing: About the Proof-of-Concept developed to test and refine the Conceptual Data Model and the OWL DL implementation.
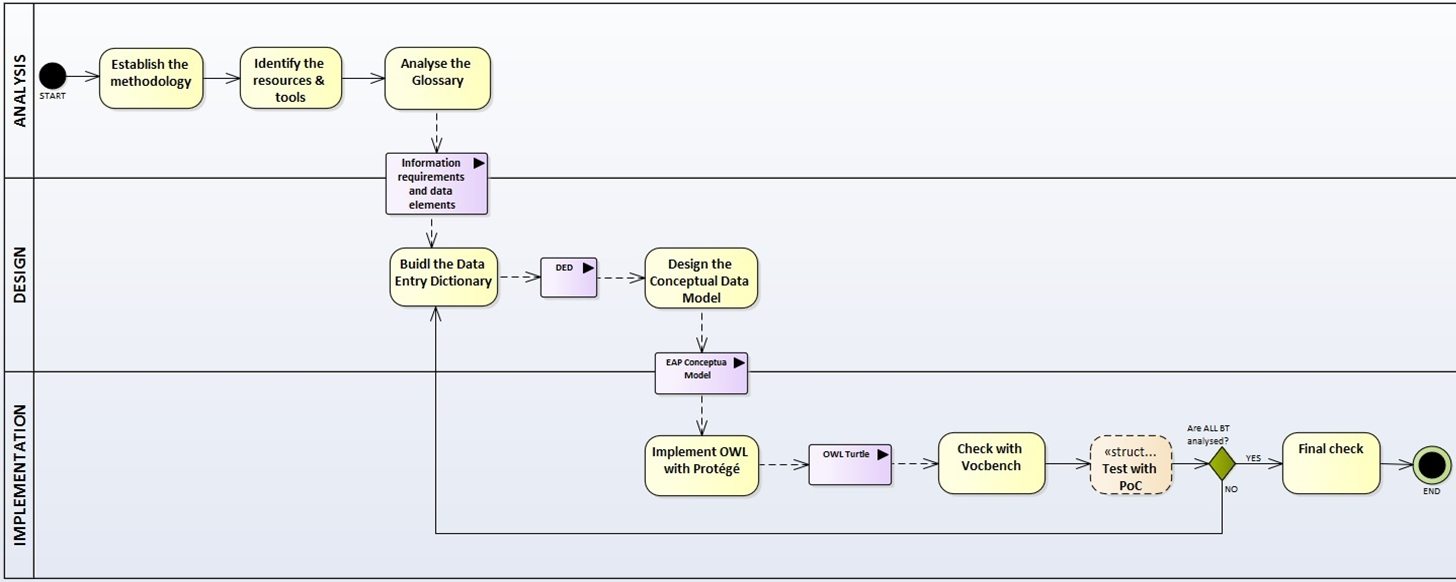
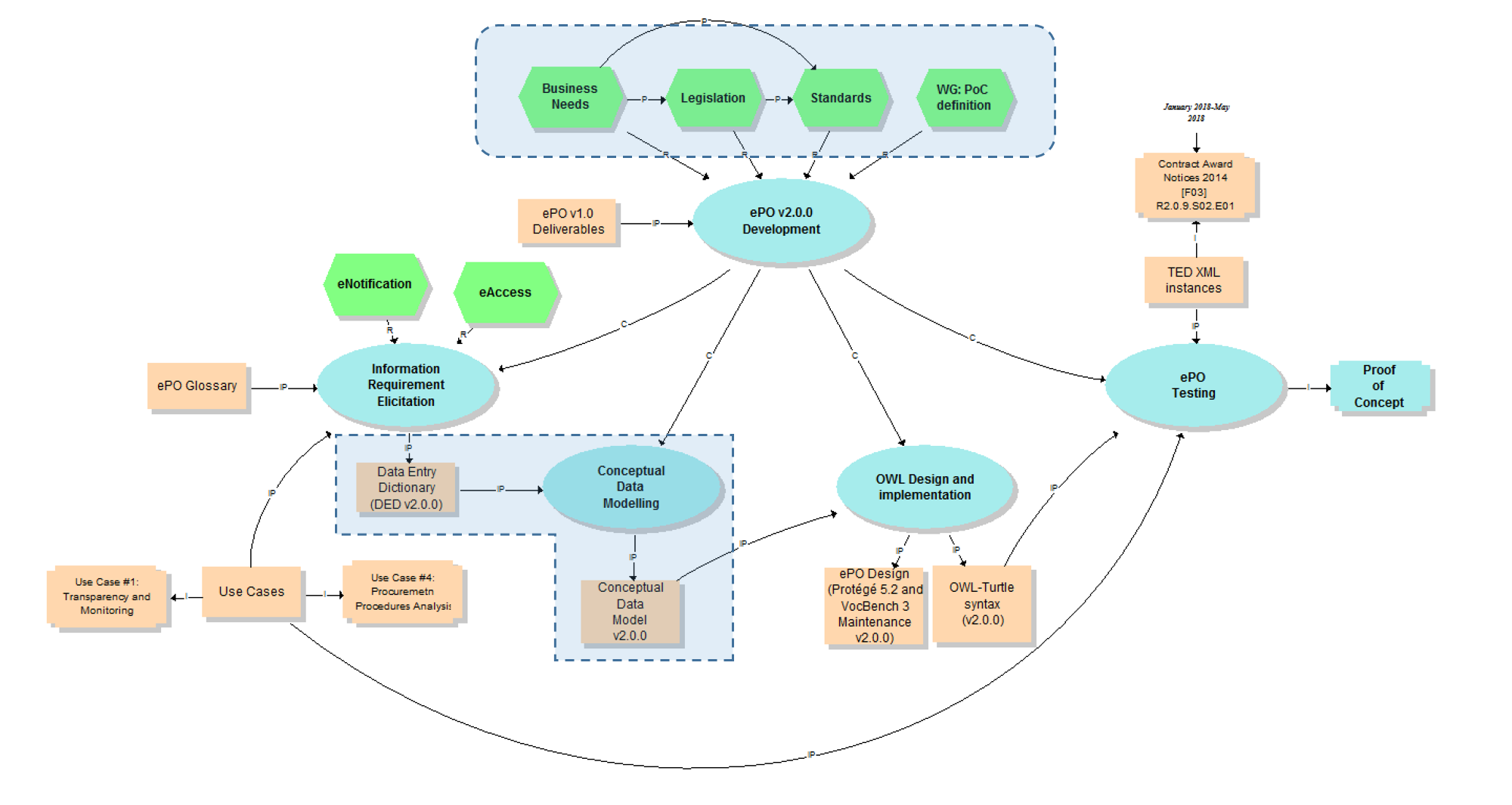
The activity diagram, below, provides a more simplified view of the recurrent (and cyclic) activities of requirements elicitation, data element definition, analysis, design, implementation and testing:
Methodological approach
To reach the strategic objectives stated above this version 2.0.0 of the ePO proposes to evolve the previous v1.00 based on a few global principles:
-
Business and Information requirements cannot contradict the EU and the Member States legislation;
-
Information Requirements should be identified through the analysis of the business processes;
-
This version 2.0.0 takes as inputs works like the CEN/BII Workshops, the standard forms and notices published by the Publications Office, DG GROW’s ESPD-related developments, the eSens developments on the VCD and the ESPD (see the ESPDint project), as well as international standards like UN/CEFACT and OASIS UBL. Most of them used an UN/CEFACT Universal Method Modelling (UMM) approach that represent the "value-chain Use Cases" to identify the information requirements exhaustively. The "value chain Use Cases" eNotification and eAccess are described in these works and cast lists of information requirements and business rules.
-
-
Use Cases around the policy area should be defined to (i) complement the identification of information requirements; and (ii) test the completeness, correctness and performance of the Ontology;
-
Use Cases defined in the ePO v1.00 are essential instruments to complete and test the information requirements elicited during the analysis of the business processes. In this version we propose to focus on the "Use Case 1: Data Journalism" and the Use "Case 4: Analysing eProcurement Procedures", as these cases provide the largest part of the requirements necessary to implement and test the eNotification and eAccess phases which is the object of ePO version 2.0.
-
-
Reuse of ontologies:
-
There is no point in reinventing models that already exist and are reusable. That is the case, for example, when representing entities such as natural persons, legal persons, addresses, etc. Hence, for generic ontologies, we proposed to reuse: ISA2’s CCEV (Core Criterion and Evidence Vocabulary), W3C’s (Organization ontology), skos (Simple Knowledge Organization System) and vCard (Virtual Contact File; originally proposed by the Versit Consortium); foaf (Friend of a Friend).
-
Other lexical (non-ontological) resources and good practices have been taken as models to inspire the drafting of sub-vocabularies to be imported and reused by the ePO. This has been the case of the CCTS (Core Component Type Specification Identifier, Amount, Quantity and Measure [5]); and UBL-2.2 (OASIS Universal Business Language, just the Period element, for the time being).
-
Finally, the inputs from other ontology developments have been, and still are, appreciated and welcome. Thus the OCDS (Open Contracting Partnership) and PPROC (Public Procurement Ontology) vocabularies have been taken into consideration.
-
-
The Ontology must always be tested and perfected using a sufficiently large sample of real data;
-
The analysis and design of an Ontology cannot be declared as finished unless it is tested. The Use Cases are only one of the essential elements to reach this goal. However the testing cannot be trusted unless the data used are not (i) abundant, (ii) real data, and (iii) with a certain degree of quality. In the case of the eNotification and eAccess phases the use of the Tender Electronic Daily (TED) platform was proposed to retrieve, transform and load the data contained in Contract Award notices. This type of notice contains the richest data related to the procurement procedure and the contract awarded.
-
| The present development (this phase of the ePO v2.0.0, including eNotification and eAccess) includes a Proof-of-Concept aimed at testing the design and performance of the Ontology. See Chapter V. Proof of Concept. |
Notice however that the A-Box was loaded only with data extracted from the Contract Notices published between January to May 2018 (the reason for this being that for transparency and monitoring the OP’s TED form F03 (Contract Award Notices) contain the most interesting data).
The ETL software, however, can be configured to extract and load data from other TED forms. See the section
ETL configuration about the configuration of the file epo.properties.
ePO governance
In order to develop these global deliverables the following Governance Structure, the following roles and responsibilities were established in ePO v1.00 and are still valid for the governance of the ePO v2.0.0:
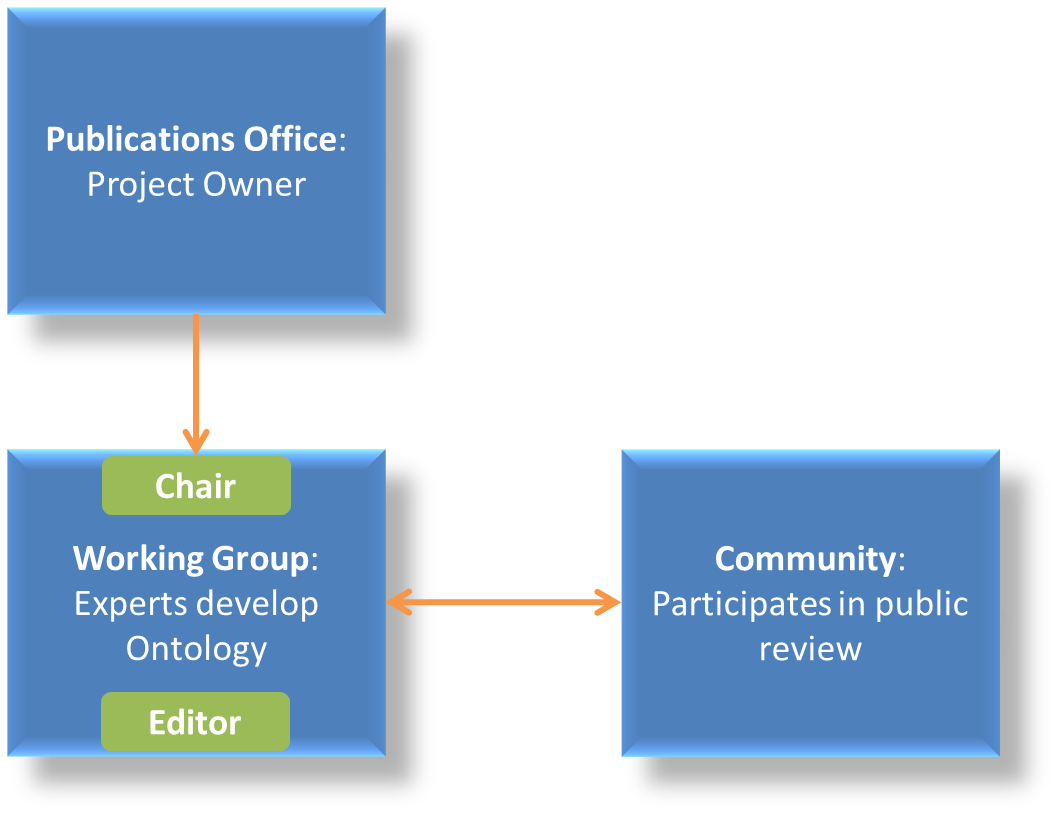
With the following roles and responsibilites:

For more details on the members of each governance body see the document D04.07 Report on policy support for eProcurement, eProcurement ontology; e.g. "Editors: are responsible for the operational work of defining and documenting the ePO".
II. Information Requirements
According to the development plan, the first task was the identification of information requirements, axioms and business rules. For this the version 2.0.0 of the ePO has taken into account the following inputs:
-
The "Use Case 1: Data Journalism" and the Use Case 4: Analysing eProcurement Procedures;
-
The Standards, business needs and Legislation** studied in the previous versions, plus the most recent developments;
-
The EU eProcurement Glossary, maintained by the ePO Working group; see Glossary Management and Glossary.
This section covers the process applied for the elicitation of information requirements (see process "Information Requirement Elicitation" highlighted with the largest semi-transparent blue box in the Knowledge Map below (rulin scope: "eNotification" and "eAccess; inputs: "ePO Glossary", "Use Cases"; output: "DED 2.0.2". The upper blue box highlights the "ruling principles" that apply to the entire development, including the elicitation of requirements.
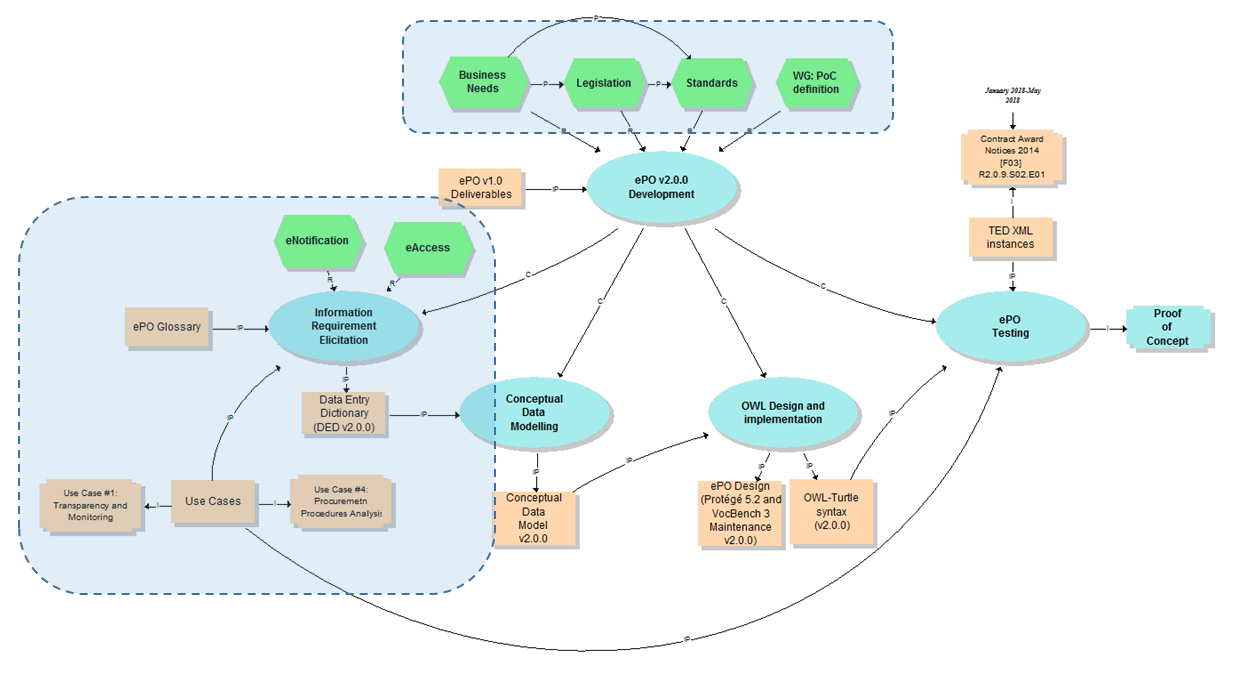
The outcome of this task are namely two artefacts:
-
The Information Requirements identified in ePO v1.0 Information Requirements v1.00;
-
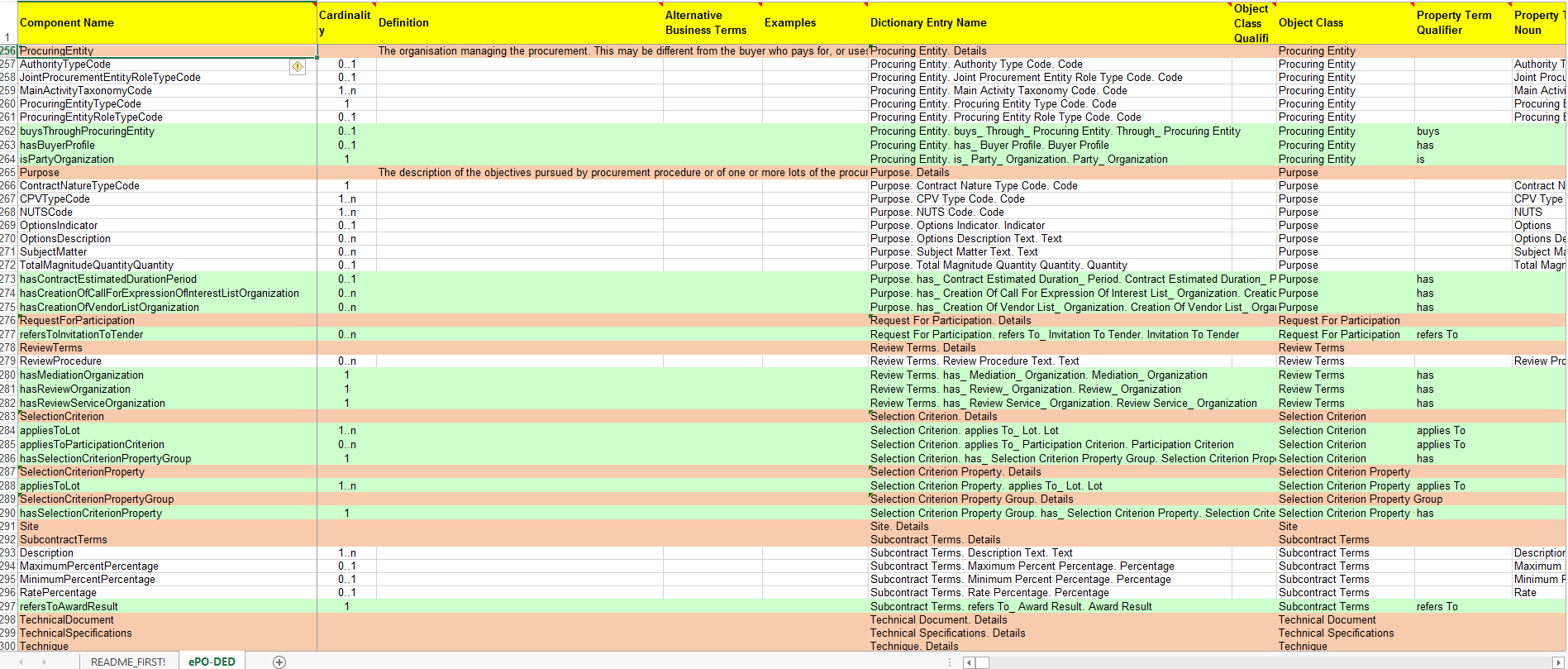
The Data Element Dictionary (DED v2.0.0): a spread-sheet where the Use Case information requirements are broken down into more detailed information requirements, axioms, business rules and annotations resulting from the analysis.
The Data Element Dictionary (DED v2.0.0)
Information Analysts need to, based on each information requirement, make decisions like determining whether an element is an entity representing a class of objects, an attribute of the class of a basic data type e.g. a code, an identifier, a date, a time, a text, etc.), or a more complex data object associated to the class (e.g. another class).
One way of listing this information is using a Data Element Dictionary, a table (e.g. a spread-sheet) with the following columns and rows:
Uses of the DED
The DED is normally used with three objectives:
-
To help analysts design the Ontology. The DED is a "logical artefact". It takes the "Conceptual Data Model" as an input and reflects the conceptual model and adds more technical details, such as all object and data properties of each class, their axioms and constraints. Sometimes, as it has been in our case, it is developed simultaneously with the Conceptual Data Model;
-
To maintain the definitions of the data elements. The ePO Glossary contains mainly the definitions of the concepts used in the Ontology. The DED takes the definitions of the ePO Glossary for the classes and adds definitions for each property of each class;
-
To identify reference data linked to the data elements, i.e. code lists and taxonomies;
-
To automatise the production of the model into different syntax bindings. The DED is usually kept as a spread-sheet. This spread-sheet can be easily used to generate XML, OWL or other machine-readable renditions of the data model. Thus it could be used to generate automatically the OWL-TTL expression of the ePO Ontology. Specifications like UN/CEFACT and UBL use the DED to automatically generate XSD schemas fully annotated (documented) with the data element definitions, examples, etc. This also facilitates the registration of these data elements in registries for their automatic discovery and cross-sector mapping (See ISO 11179-6:2015 Registration parts for more details on this).
Current status of the DED
The DED depends on the Glossary definitions and on the Conceptual Data Model, amongst other inputs for the elicitation of information requirements. The ePO Glossary is currently under revision by the members of the Working Group. This revision makes evident how the Conceptual Data Model can be improved.
As the ePO Glossary is an ongoing work the DED cannot be considered finished. Additionally many of the DED properties will have to be defined based on their context, the class where they belong in. These definitions are being worked on during the discussions about the ePO Glossary with the Working Group.
Content of the DED
To the effects of using the DED to get a quick glimpse of the terms used in the ePO, their definitions just look into the columns "Component Name" and "Definitions". The rest of columns are used to indicate the cardinality of the data element, to compose the name of the class or property, and other information needed during the transformation of the DED into a specific syntax (e.g. into XML, Turtle, etc.).
The colour of the rows mean is intended to distinguish classes from properties:
-
"Pink rows": represents a class. The rows between one pink row and another are the content of the class;
-
"Transparent rows": represent a property of a class the range of which is an attribute (simple data type);
-
"Green rows": represents a property of class the range of which is another class of the Ontology.
III. Conceptual Data Model (CM)
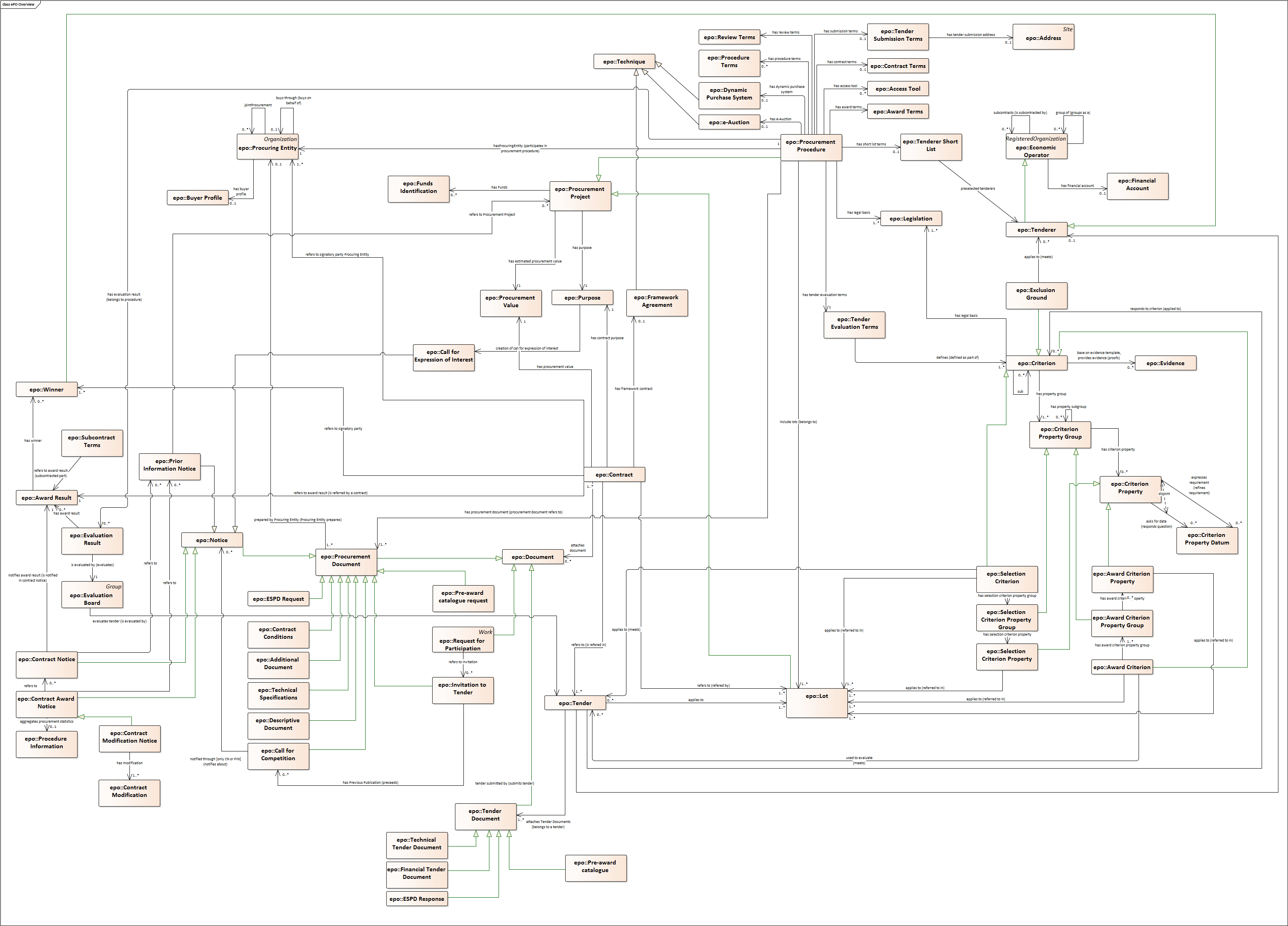
The construction of the DED ran in parallel to the drafting of the Domain Conceptual Data Model. Up to nineteen diagrams have been drafted. seventeen of them cover specific "topics" in the scope of eNotification and eAccess, e.g. Procurement Project, Procurement Procedure, Procuring Entity, Economic Operator, Lots, Procurement Terms, etc. An additional "overview" diagram provides a general view of the whole model. Data types are put together in its own diagram, too.
This section covers the development of the Domain Conceptual Data Model (see process "Conceptual Data Modelling" highlighted with a blue inverted "L" in the Knowledge Map below (input: "DED 2.0.2"; output: "Conceptual Data Model v2.0.2").
The conceptual data model is available both as an XMI format [6] and Enterprise Architect project file.
CM Overview
General view of the Classes and relations of the ePO v2.0.0 Ontology. Keep in mind that for this version the focus was put on e-Notification and e-Access.
| Beware that this Conceptual Data Model is right now being reviewed by the Working Group (WG). This revision, is available through the GitHub wiki page and takes also into account the on-going revision of the ePO Glossary by the WG. Once reviewed, the OLW-TTL will be re-drafted, too. See all the menu entries on the right side of the GitHub wiki page (marked with the version number "v2.0.1" and the note "(under revision)". |
How to read the diagrams
The subsections below provide further details on key Classes of the ePO and about how these Classes relate to other Ontologies. A brief description for each model is provided in order to make it more understandable. The "legend" below should also facilitate the comprehension of the diagrams content.
-
Boxes in colour beige are Classes, i.e. main entities of the ontology, like "Procurement Procedure", "Procuring Entity", "Economic Operator", etc.;
-
Classes may contain codes. In this representation, the ePO codes are not included inside the Class but are represented as associations of the Class to a specific enumeration element. The name of the code is built upon the verb "uses" and the name of the enumeration. Thus the triple used to say that a Procurement Procedure is of type Open is expressed like this in the OWL-TTL:
-
:ProcurementProcedure :usesProcurementProcedureType epo-rd:ProcurementProcedureType, where:is the default prefix representing the ePO ontology andepo-rd:is the prefix reserved for the namespace representing all the codes defined in ePO (eProcurement-specific, to be located in the OP’s Metadata Registry (MDR)).
-
| See also the section "Codes and Identifiers", in chapter "IV. Design and implementation" for details on the implementation of these. |
-
Boxes in colour green are "Code Lists", i.e. enumerations of disjoint concepts represented with a code);
-
Classes associate other classes via "object properties", i.e. directed association arrows ("predicates", from the ontology perspective) that have a class at the origin (the subject of a triple, in the ontology) and another class at the end of the link (the "object" of the triple).
-
"Data properties", i.e. links between the Class and more primitive/basic elements, are represented as attributes of the Classes. These attributes appear as lines of text inside the box representing the Class, e.g. see the attributes "Description: Text[0..*]", "ID: Identifier [0..1]" and "Title: Text [0..1]", inside the Class "Procurement Project".
-
Associations between Classes are represented as unidirectional arrows to keep the diagrams simple. However, when the association is bi-directional it is indicated with two predicates and the second one is enclosed with parenthesis "()". In the OWL-TTL these are declared as "inverse" properties. Examples: "Procurement Procedure includes lots (belongs to) Lots", in the diagram, is to be read as:
-
"Procurement Procedure includes one or more Lots", and
-
"One Lot belongs to one Procurement Procedure";
-
Procurement Project
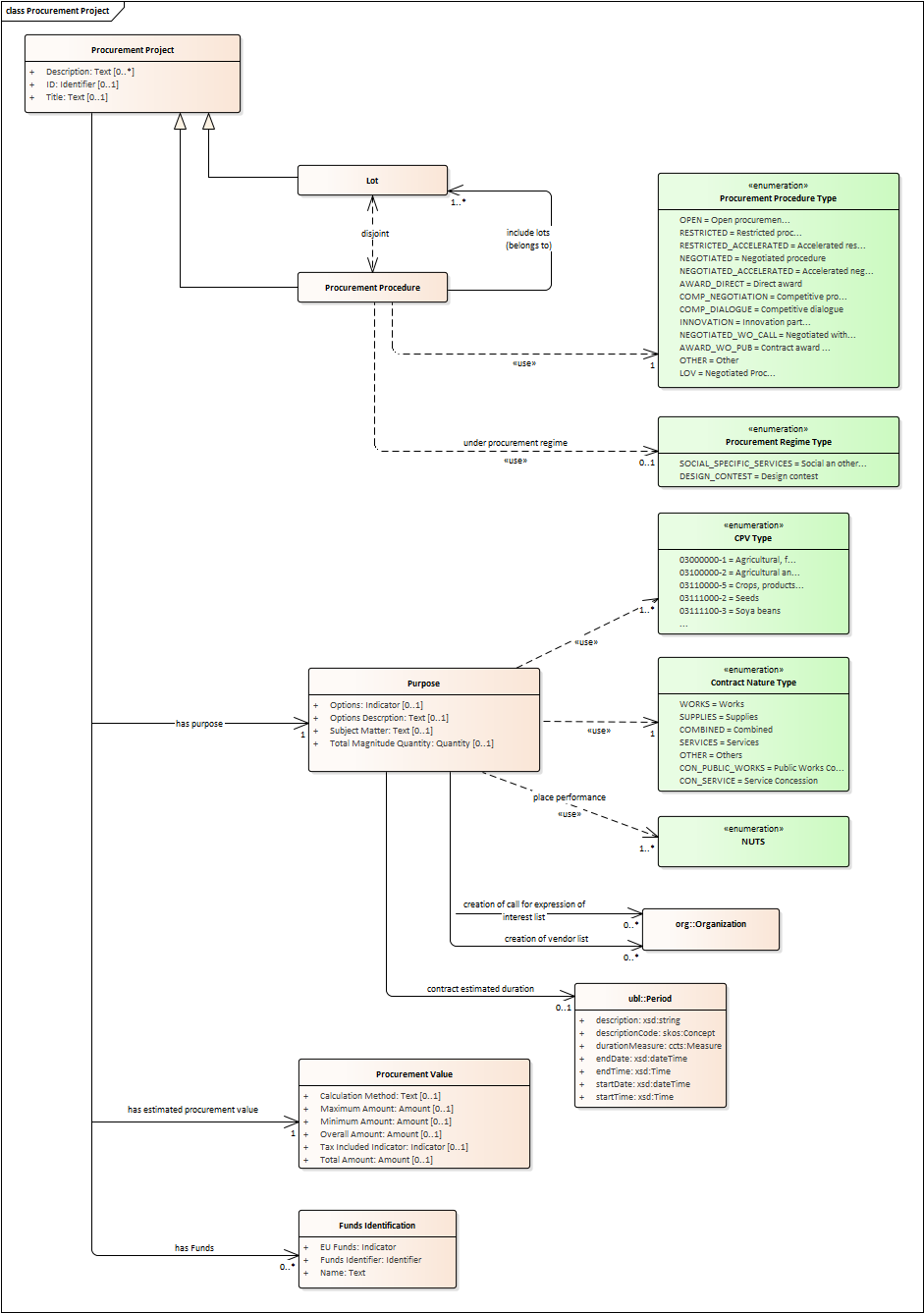
-
Procurement is the acquisition by means of a public contract of works, supplies or services by one or more contracting authorities from economic operators chosen by those contracting authorities, whether or not the works, supplies or services are intended for a public purpose. (Directive 2014/24/EU, Article 1(2)).
-
At its inception phase, the Procurement can be thought as a "Procurement Project".
-
Procurement Projects are implemented through a Procurement Procedure or through the Lots of a Procurement Procedure.
-
Procurement projects have a purpose which include aspects such as the subject-matter, the place of performance, contract nature, estimated duration, and other elements.
-
The Procurement Project has an estimated value. These estimations are later on confirmed or finally established and reflected in the Contract and announced through the Contract Award Notice.
-
The Procurement Project may use Techniques (see Technique Type).
-
The Procurement Project may use Funds provided by the European Union.
Procurement Procedure
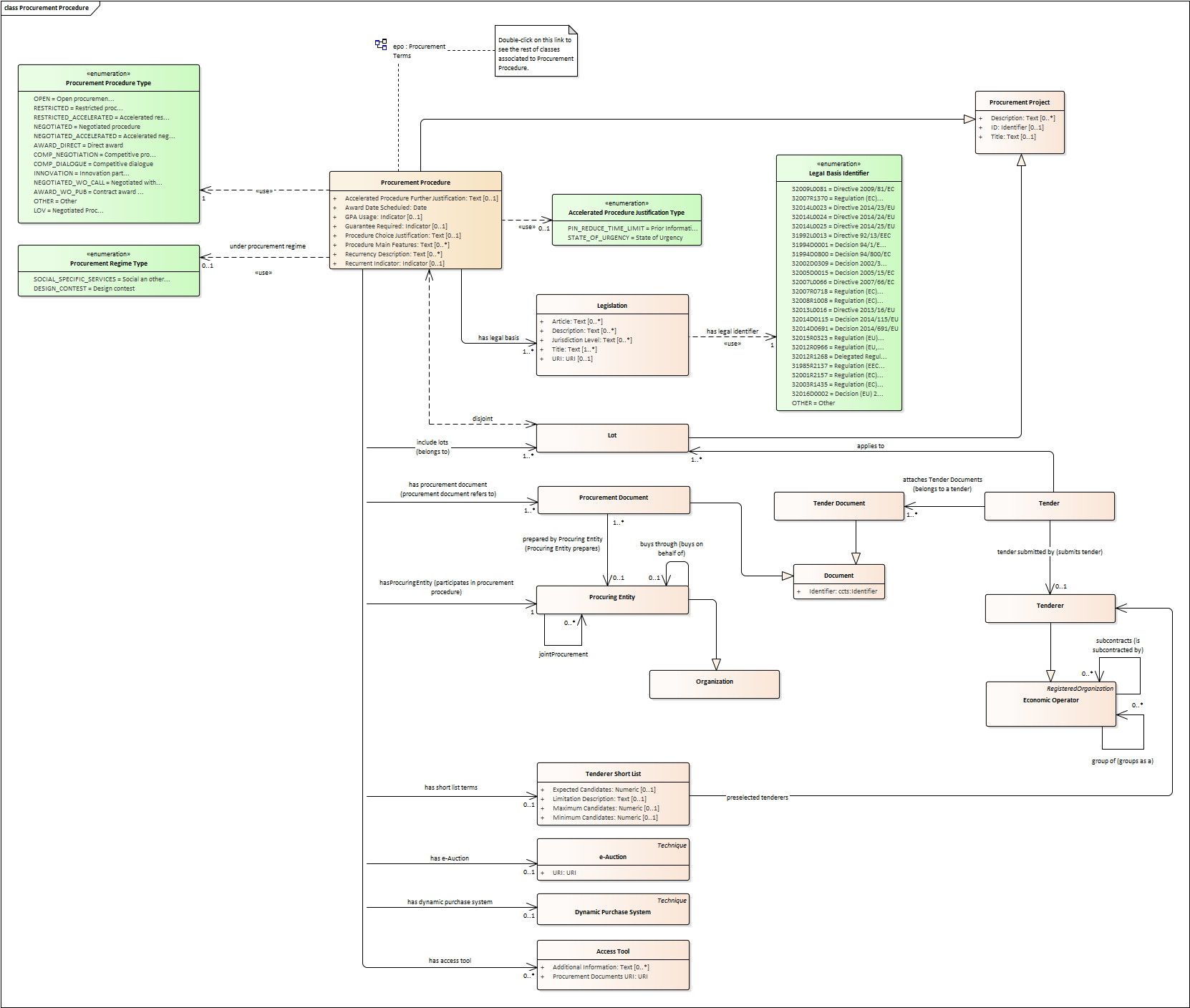
-
Procurement Procedures is a series of activities leading to the conclusion of a public contract.
-
Pay attention to the fact that the Procuring Procedure is not directly linked to the Contract. Instead, this connection is made through the Procuring Entities involved in the Procedure. There are different reasons for this: e.g. if no Tenders are submitted for a Procedure, no Contract is issued, which also entails that the link could not be established through the Tender. This also explains why Economic Operator is not directly related to the Procurement Procedure.
-
Different types of Procurement Procedures are carried out according to the EU Legislation (see Procurement Procedure Type).
-
Some Procurement Procedures apply specific legal regimes and instruments for the awarding of certain services or the acquisition of designs (see Procurement Regime Type).
-
Procurement Procedures are divided in one or more Lots (see diagram Lots).
-
Procurement Procedures usually generate, collect or refer to different documents. Two of the most relevant groups of documents are represented by the classes Procurement Document and Tender Document (see diagram Documents).
-
All Procurement Procedures are conducted by at least one Procuring Entity, in some cases Procuring Entities carry out join procurement (see diagram Procuring Entity).
-
Procurement Procedures may need to refer to certain types of organisations responsible for the management or control of a number of aspects of the procedure, e.g. environmental party, tax party.
-
In some types of Procurement Procedures (e.g. restricted, competitive with negotiation, other), Procuring Entities may limit the number of candidates accessing the award criteria phase. When this is the case, certain information must be notified by the Procuring Entity, e.g. expected maximum and minimum number of candidates, justification / description of the limitation, etc. (Tender Short List).
Accelerated Procedure
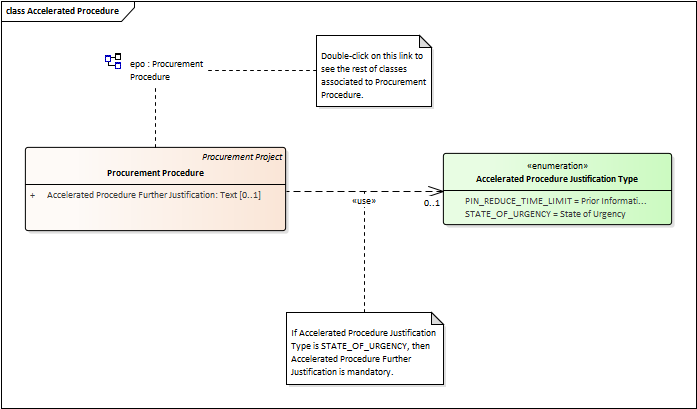
-
An accelerated procedure takes place when the time limits within the procedure are reduced.
-
Time limits can be reduced due to as state of urgency (Accelerated Procedure Justification Type) in which case a justification must be provided (Accelerated Procedure Further Justification).
-
They can also be reduced by a Prior Information Notice (PIN) published specifically for reducing the time limits.
-
For example see Directive 2014/24/EU Article 27(3) and 28(6).
Procurement Terms
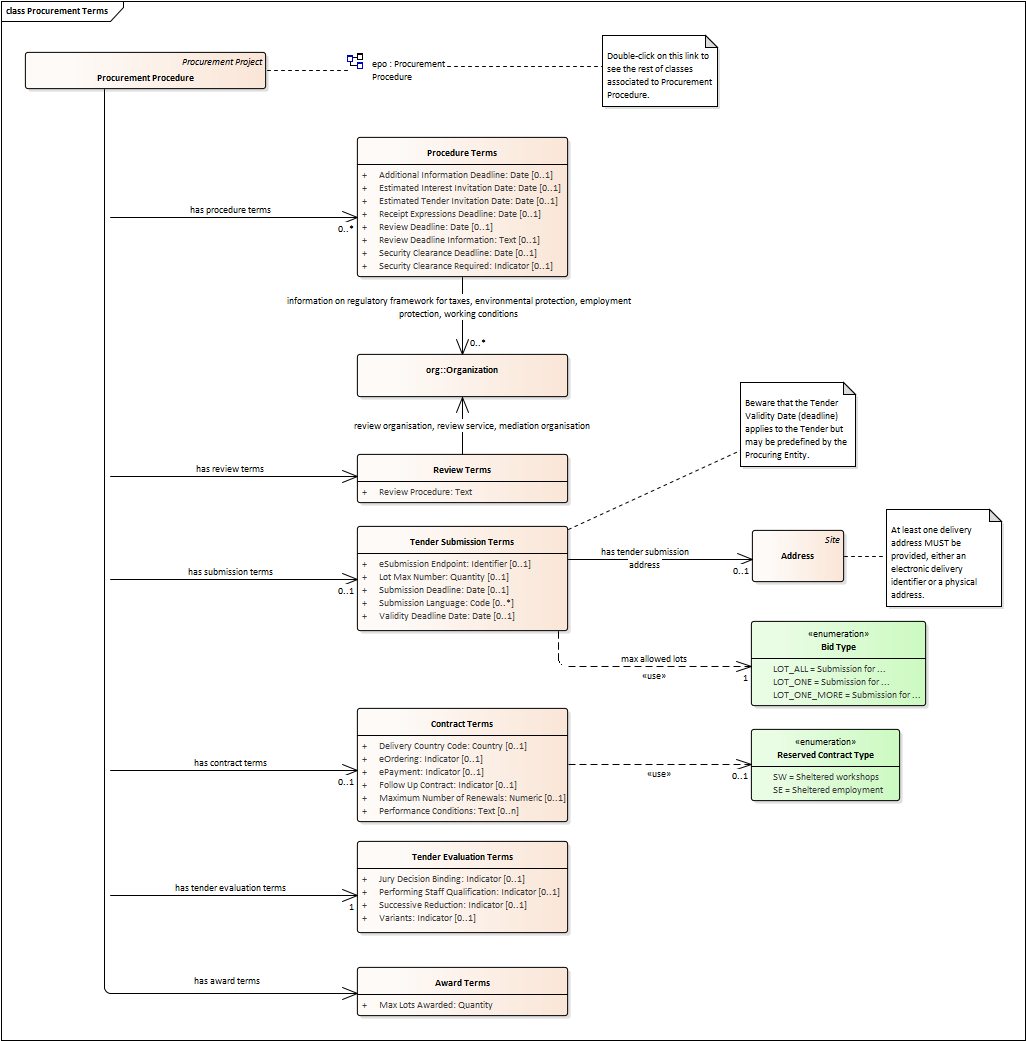
-
The Procurement Terms are "conditions or stipulations established by the Procuring Entity:
-
Procedure Terms: conditions and stipulations determining how the procurement procedure is executed.
-
Review Terms: conditions and stipulations about the information and organisation responsible for the revision of a Procurement Procedure.
-
Tender Submission Terms: conditions and stipulations about the Tender and its submission.
-
Contract Terms: conditions and stipulations related to the implementation of the contract.
-
Tender Evaluation Terms: conditions and stipulations to evaluate the tenders.
-
Award Terms: conditions and stipulations to determine how the procurement procedure is awarded.
-
Lots
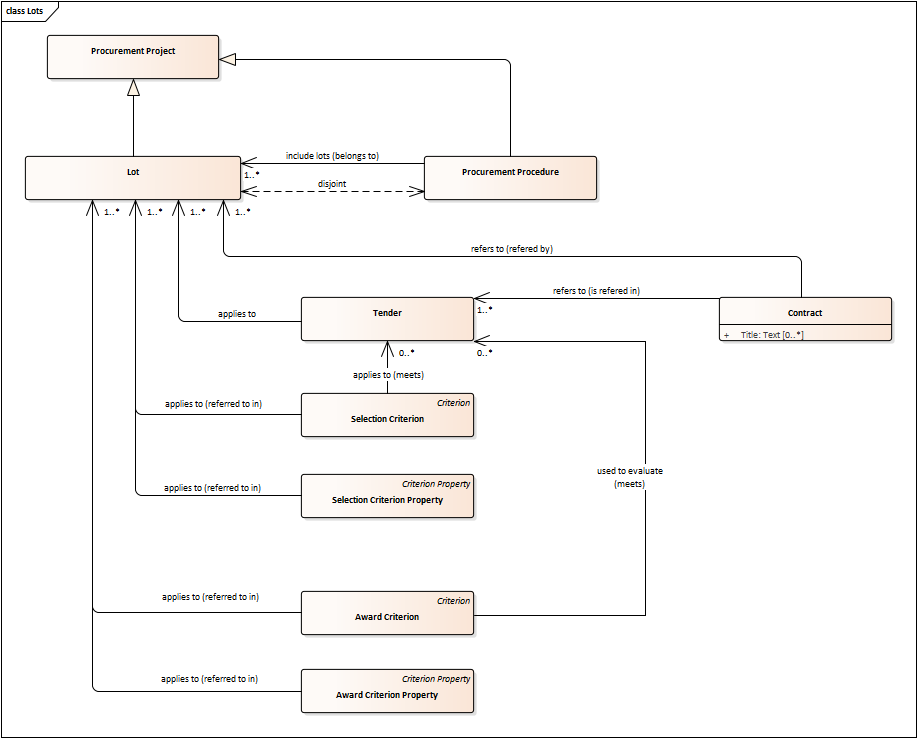
-
A Lot is one of the parts into which a Procurement Procedure is divided.
-
One or more lots may aim at one or more Contract.
-
When preparing the Procurement Projects, Lots may be grouped.
-
Tenderers prepare their Tender for one or more Lots.
-
The Procuring Entity apply Selection and Award Criteria to one or more Lots or Group of Lots.
Technique
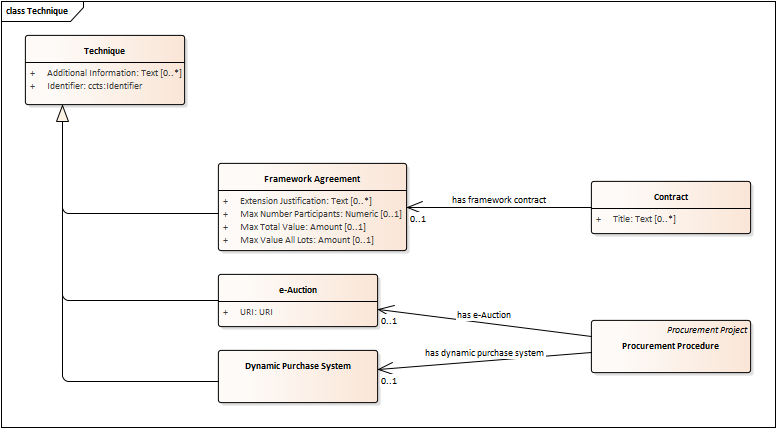
-
Techniques are specific methods of carrying out the procurement or a purchase. E.g. Framework Agreement, e-Auction or Dynamic Purchase System.
-
Each Technique has its own properties, thus Framework Agreement can be typified, has a duration, its own values, etc.
Procuring Entity
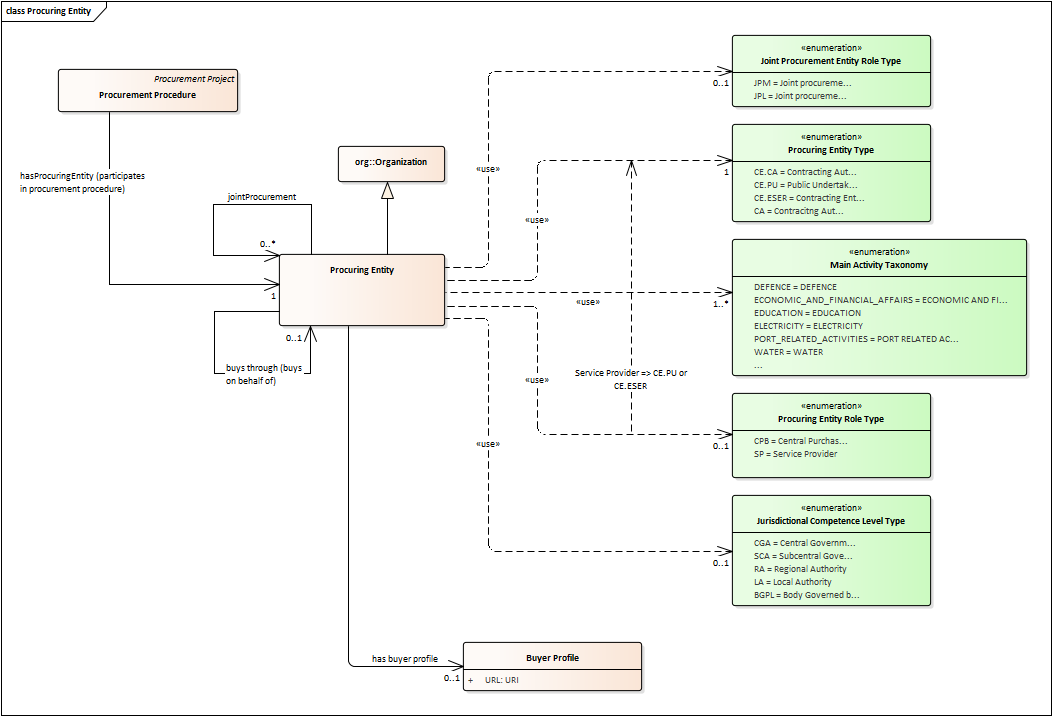
-
In any Procurement Procedure, there is at least one Procuring Entity;
-
Procuring Entities are “Organizations”, appropriately identified and described (IDs, Names, Addresses, Contact Points, etc.);
-
Depending on its nature and main activity a Procuring Entity may be identified simply as a Contracting Authority (general procurement) or as a Contracting Entity pursuing the procurement of gas and heat, electricity, water, transport services, ports and airports, postal services and extraction of oil and gas and exploration for, or extraction of, coal or other solid fuels. A Contracting Entity may in turn be a Contracting Authority, a Public Undertaking or entities with special or exclusive rights (Procuring Entity Type code list);
-
For some Procurement Procedures, a Procuring Entity can join other Procuring Entities (Joint Procurement)
-
In these cases, the Procuring Entities participating in the Joint Procurement adopt one role (Procuring Entity Role Type code list), e.g. the lead of the group.
-
Procuring Entities are in general responsible for the both the management of the procurement procedure and the purchase. However in some cases procuring entities may buy on behalf of other procuring entities or through other procuring entities ("Procuring Entity Role Type").
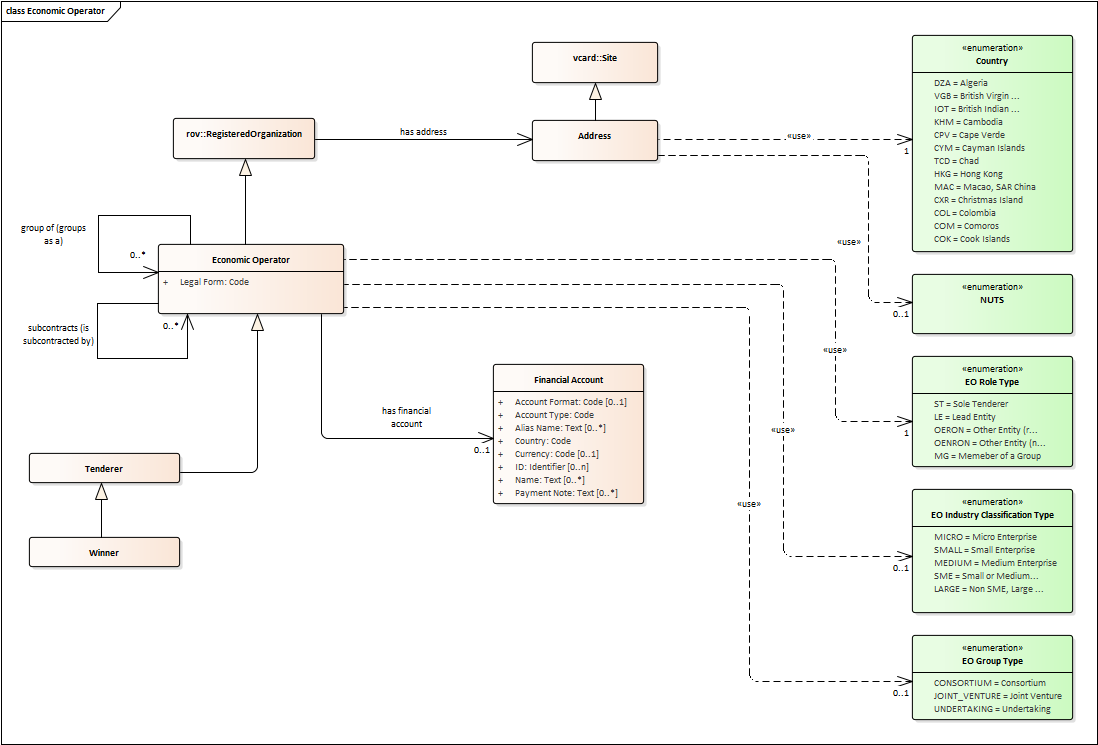
Economic Operator
-
An Economic Operator is an organisation.
-
Economic Operators can be Tenderers (the submitter of the Tender) or sub-contractors.
-
When the Economic Operators are members of a group (e.g. Consortia, Joint ventures, Undertaking (EO Group Type)), and they play different roles, e.g. group lead entity, member of the group, etc. (EO Role Type).
-
The Winner of a contract is a tenderer or group of Tenderers.
-
Tenderers may rely on other Economic Operator that are subcontractors but not tenderers.
-
When guarantees are required by the Procuring Entity, Economic Operators may have to provide Financial Account details (e.g. a bank account data).
Contract
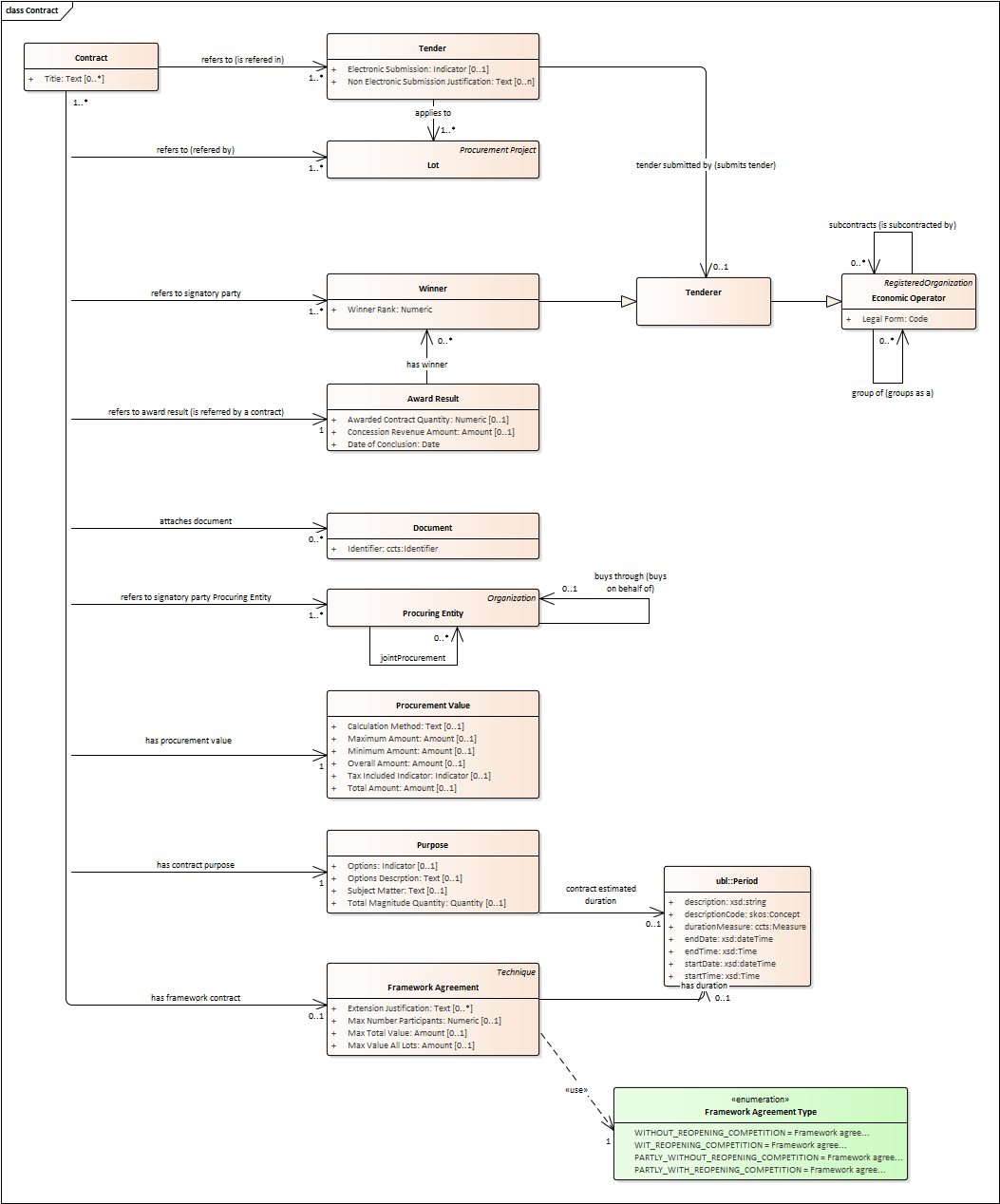
-
One of the activities that takes place in the Procurement Procedure life-cycle is the evaluation of Tenderers and Tenders, and the awarding of a contract to one or more Tenderer. The awarded Tenderer(s) are the "Winner(s)".
-
The Contract may attach other Procurement Documents and other types of Documents.
-
The object of the Contract and additional data that where stated in the Procurement Project are also placed in the contract Purpose (e.g. Subject Matter, Place of Performance, Total Magnitude Quantity, etc.).
-
Similarly, the values of the Procurement that where initially estimated in the Procurement Project are set in the Procurement Value class.
-
The Contract reflects also the Awarding Results (resulting from the evaluation) and the signatory parties (Procuring Entities and Winners).
-
In case the Procurement Procedure uses Framework Agreement as Technique, the contract refers to it.
Tender
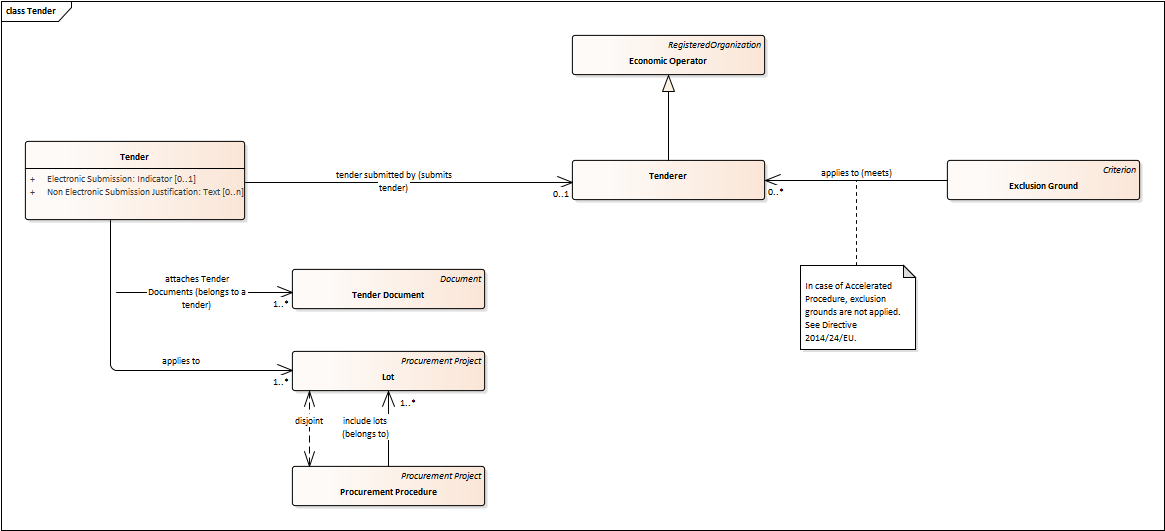
-
Tenders are submitted by Tenderers, who are Economic Operators.
-
One Tender may attach one or more "Tender Documents" (e.g. the Financial Tender, the Technical Tender, Technical annexes and specifications, etc.; see the Diagram "Documents");
-
In Procurement Procedures divided into Lots, one Economic Operator submits one Tender. The tender specifies to which Lots it applies.
-
Procurement Procedures are always considered to have at least one lot.
Evaluation Result
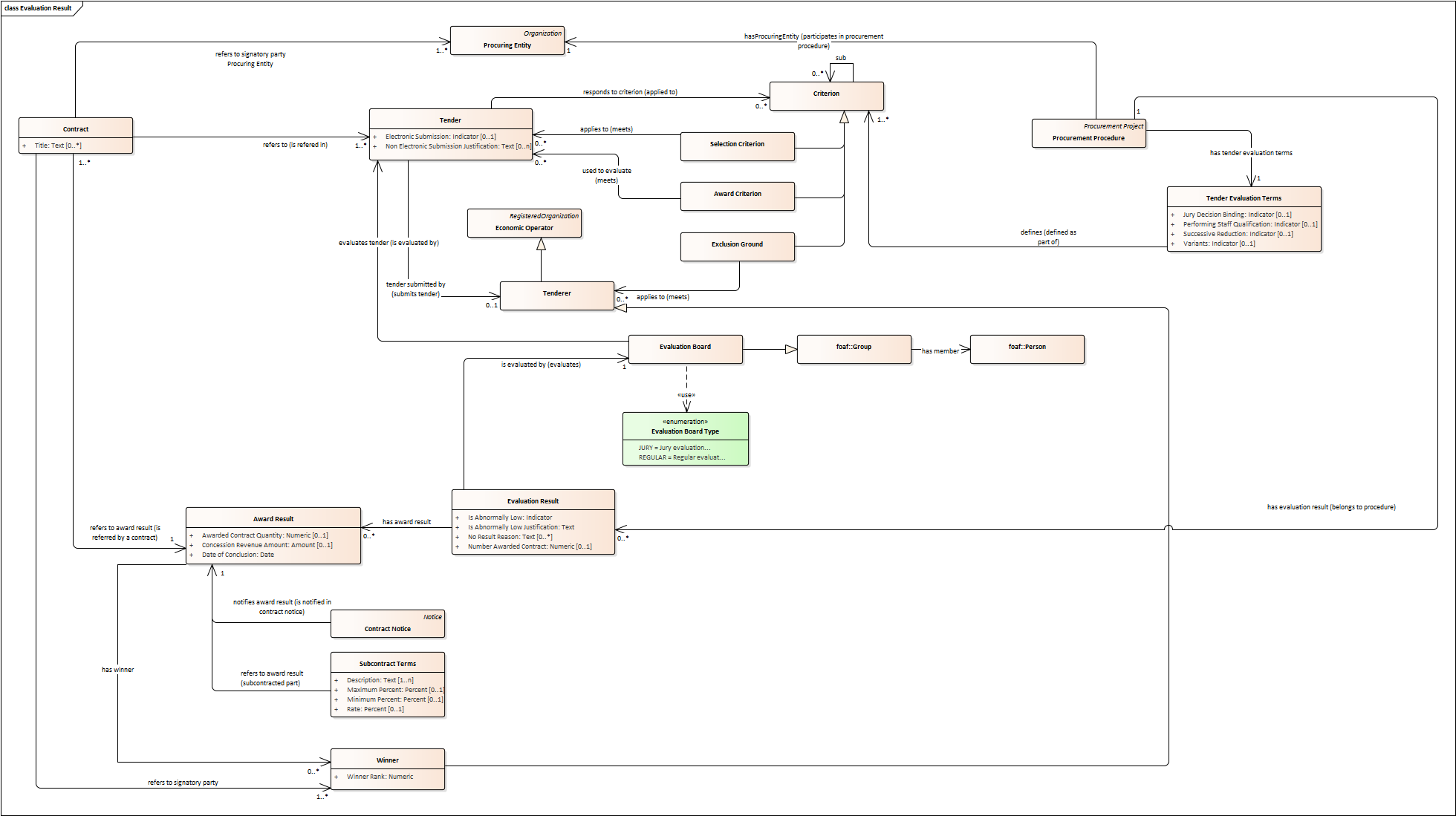
-
The Evaluation Result is presented in the form of a report showing the assessment of the tenders by the evaluation board.
-
The Evaluation board takes into consideration the Criterion and the Tender Evaluation Terms when assessing the tenders.
-
The awards result takes into consideration the evaluation result and awards the contract.
-
In the case of contest design competitions, the board is formed by a Jury, whose decision may be binding for the Procuring Entity (see Evaluation Board Type).
Contract
-
One of the activities that takes place in the Procurement Procedure life-cycle is the evaluation of Tenderers and Tenders, and the awarding of a contract to one or more Tenderer. The awarded Tenderer(s) are the "Winner(s)".
-
The Contract may attach other Procurement Documents and other types of Documents.
-
The object of the Contract and additional data that where stated in the Procurement Project are also placed in the contract Purpose (e.g. Subject Matter, Place of Performance, Total Magnitude Quantity, etc.).
-
Similarly, the values of the Procurement that where initially estimated in the Procurement Project are set in the Procurement Value class.
-
The Contract reflects also the Awarding Results (resulting from the evaluation) and the signatory parties (Procuring Entities and Winners).
-
In case the Procurement Procedure uses Framework Agreement as Technique, the contract refers to it.
Criterion
In ePO, Exclusion, Selection and Award criteria are designed based on the ISA2’s Core Criterion and Evidence Vocabulary (CCEV).
This vocabulary was originally proposed in the context of the
ESPD Service and Exchange Data Model and e-Certis developments
(under the mandate of
Directive 2014/24/EU, Articles 59 and 61,
and the ESPD Regulation).
OASIS UBL-2.2 took also the CCEV as the basis
to model their documents Qualification Application Request and Qualification Application Response (implemented as W3C XSD schemas).
During the analysis of the ePO some aspects of this vocabulary were improved. The results of this improvement is presented in the diagram below. Please compare this diagram with the ISA2 vocabulary and the OASIS UBL-2.2 model.
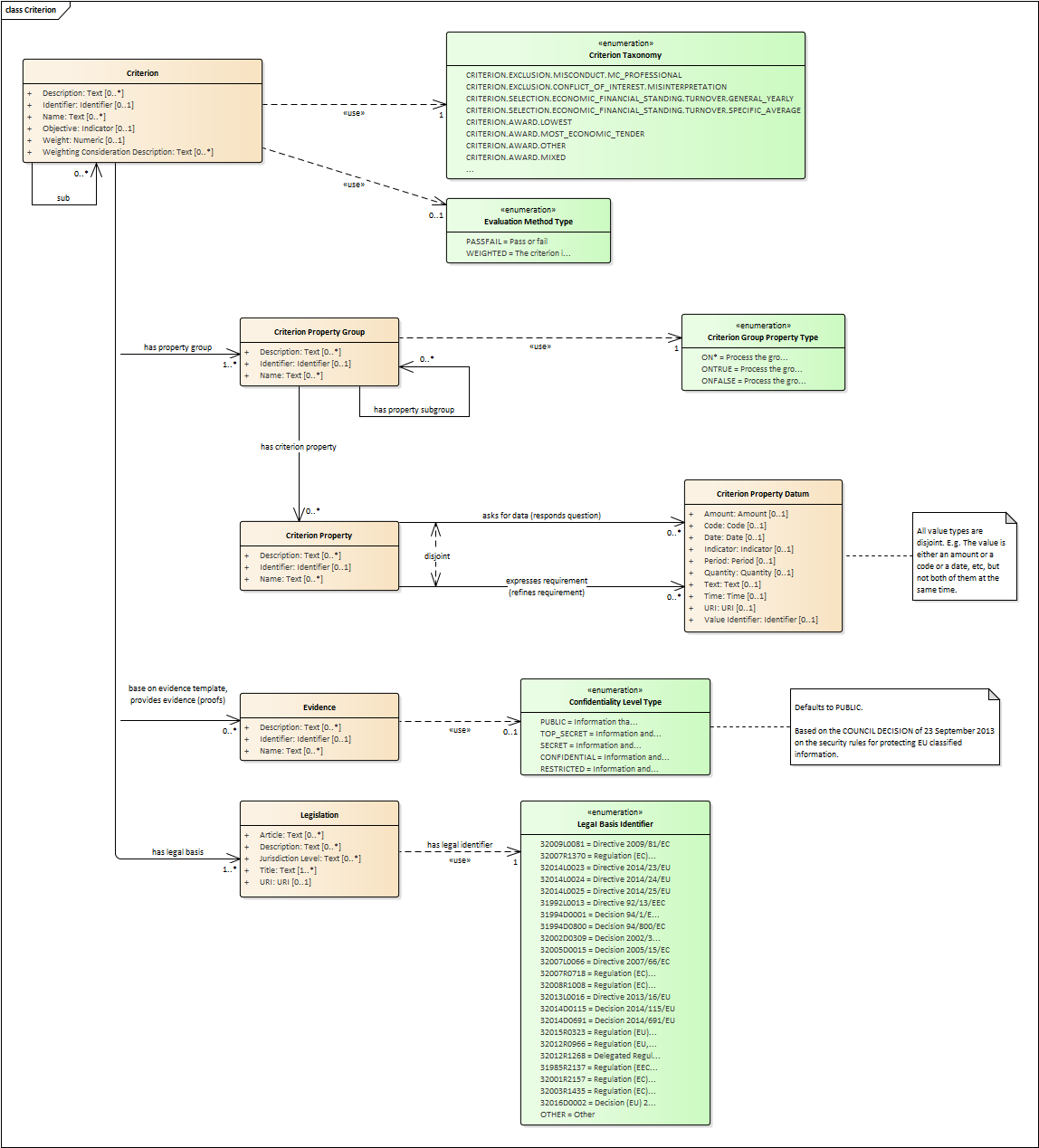
-
Criterion is a generic business-agnostic class. This eProcurement ontology (ePO) uses this as a base class to extend Award Criterion, Exclusion Grounds and Selection Criterion (see the rest of diagrams about criteria for details).
-
A Criterion is a condition that needs to be answered for evaluation purposes. For example: General average turnover for the past three years.
-
All Criteria are codified via a Criteria Taxonomy. Thus, the examples above have an associated code as exclusion, selection and award criteria (see Criteria Taxonomy). Exclusion, Selection and Award criteria do extend the classes and properties of Criterion.
-
In general, Criteria are evaluated using a pass/fail method, meaning that the Tenderer or the Tender meet or do not meet the Criterion. However, selection and award criteria may be weighted (see Evaluation Method Type).
-
A Criterion may contain sub-criteria. Thus, the exclusion criteria defined in the European Directives may be further detailed in national sub-criteria, e.g. national professional misconduct-related criteria.
-
The condition described in a Criterion may be broken down into simpler elements named "Criterion Property", which are always grouped into Criterion Property Groups.
-
A Criterion Property is a more specific information needed to measure a criterion. It is a question that usually goes hand in hand with a specific requirement. For example which follows on from the example given for criterion: Question: Amount? Requirement: The text explaining what the procuring entity is interested in measuring i.e. minimum turnover.
-
Criterion Property Groups are organised structures or related criterion properties. Following on from the example of Criterion property. In the case of a yearly general turnover that needs to specify three turnovers for three specific years, a group of properties would be: turnover 1987, turnover 1988, turnover 1989.
-
One criterion property is normally associated to a value (Criterion Property Datum). The value may be an economic amount, a text, a date or a period, etc.
-
The responses to one Criterion may be supported by one or more evidences (property "provides evidence"). This evidence might have to be based on a template specified by the Procuring Entity (property "base on evidence template"). The fact that one individual of an evidence is linked to one Criterion does not preclude the possibility of linking this same individual (or instance) to other Criteria.
-
In the domain of public procurement, exclusion grounds, selection criteria and award criteria are normally based on a specific legal framework (see class Legislation).
Award Criterion
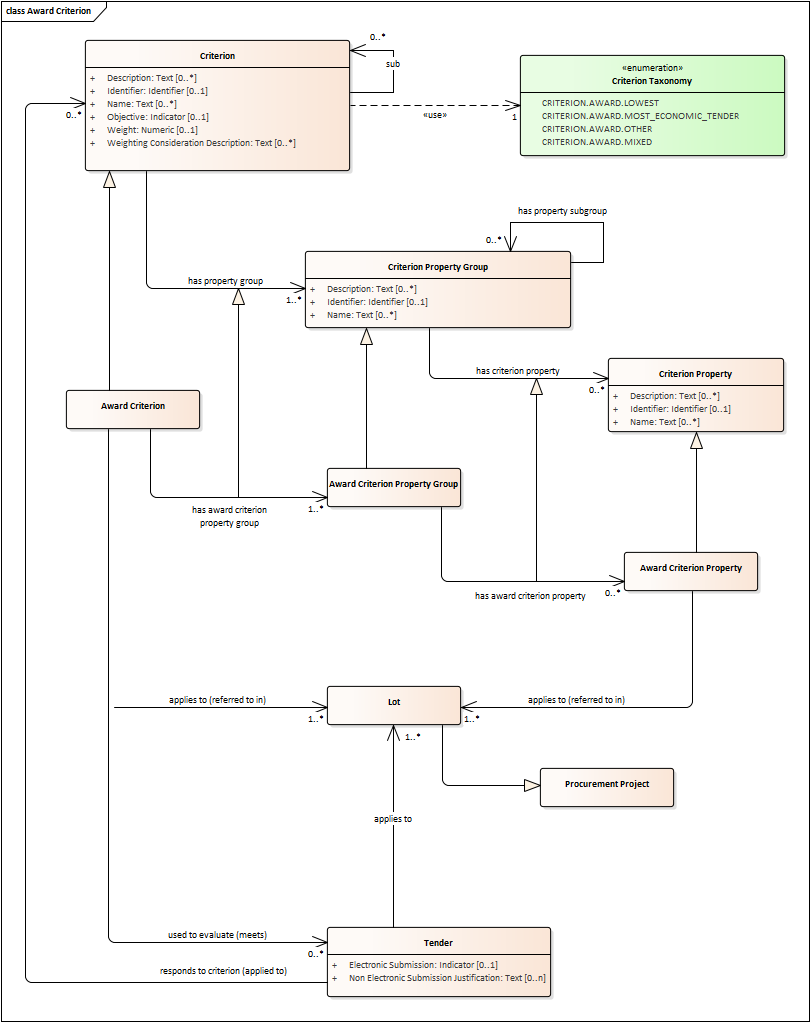
-
Award Criteria are used to evaluate Tenders. They may include the best price-quality ratio, including qualitative, environmental and/or social aspects, linked to the subject-matter of the public contract in question.
-
Thus, an Award Criterion needs to be codified as lowest, most economic tender, mixed or other (for non-objective / qualitative criteria - see Criteria Taxonomy).
-
In two-phase procedures technical and financial criteria, used in the first phase for the selection, can be reused as weighted criteria to evaluate the Tenders.
-
Award Criterion is a class that specialises Criterion. The specialisation consists in providing a property to link the Criterion to Lot.
-
Award Criterion and Award Criterion Property, both need to link to Lot.
-
This is why the class Award Criterion needs to provide specialised sub-classes for the Criterion Property Group and Criterion Property, as well as the properties linking them.
Exclusion Grounds
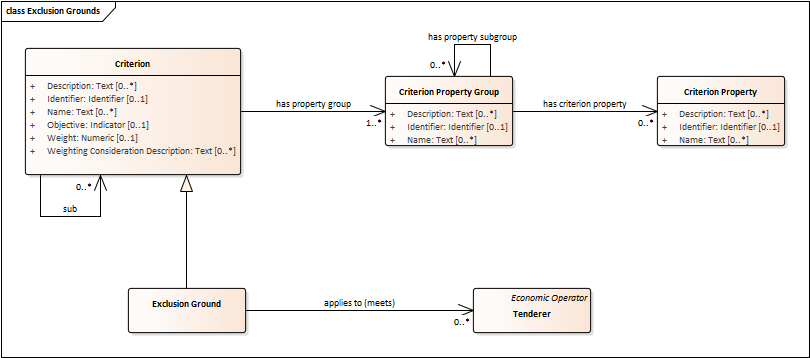
-
Tenderers may be excluded from participate in a Procurement Procedure, in case they bridge any of the legal criteria established in the Directives. This criteria are named Exclusion Grounds.
-
Exclusion Ground extends the generic Criterion class by adding a new property ("applies to") to refer to the Tenderers that are excluded in a procedure.
-
The ePO allows to determine the exact Exclusion Grounds were not met by the Tenderer for specific Procurement Procedure. To see how the Tenderer related to Procurement Procedure, please see the diagram "Evaluation Result".
Selection Criterion
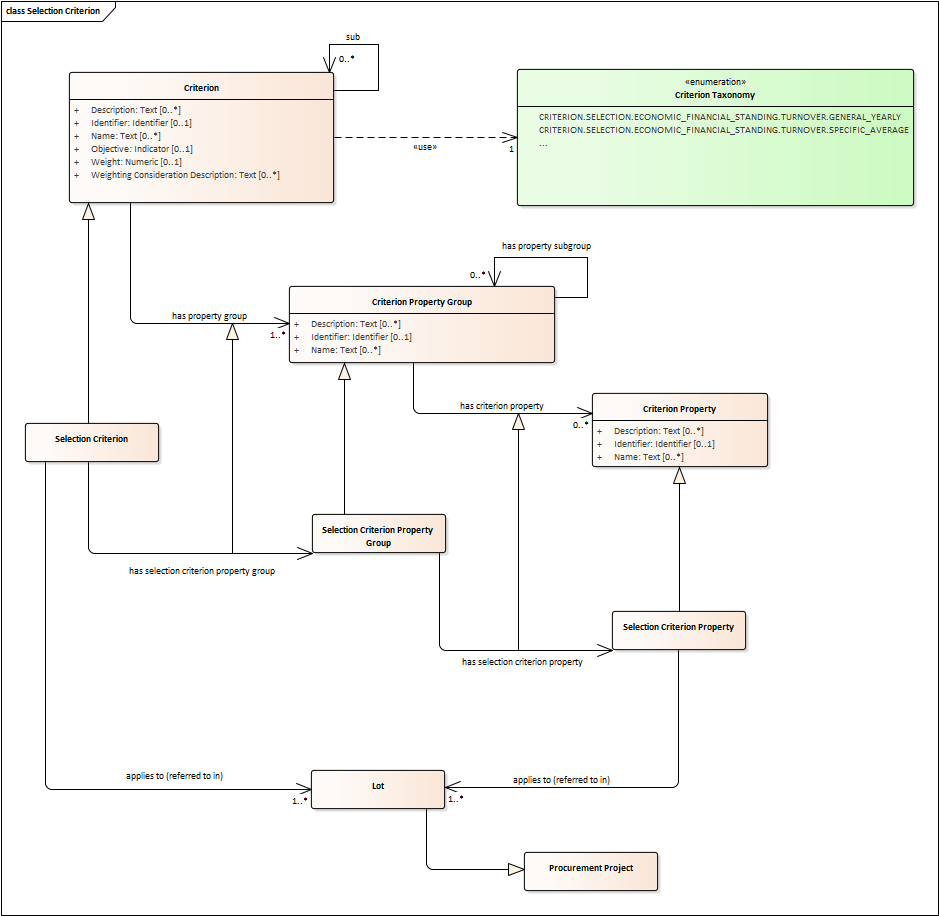
-
Selection Criteria aim at ensuring that a candidate or tenderer has the legal and financial capacities and the technical and professional abilities to perform the contract to be awarded (see ePO Glossary for the difference between Candidate and Tenderer).
-
Thus, a Selection Criterion is to be classified using the Criteria Taxonomy (e.g. CRITERION.SELECTION.ECONOMIC_FINANCIAL_STANDING.TURNOVER.GENERAL_YEARLY, CRITERION.SELECTION.ECONOMIC_FINANCIAL_STANDING.TURNOVER.SPECIFIC_AVERAGE, etc.).
-
Selection Criterion is a class that specialises Criterion. The specialisation consists in providing a property to link the Criterion to Lot.
-
Selection Criterion and Selection Criterion Property, both need to link to Lot.
-
This is why the class Selection Criterion needs to provide specialised sub-classes for the Criterion Property Group and Criterion Property, as well as the properties linking them.
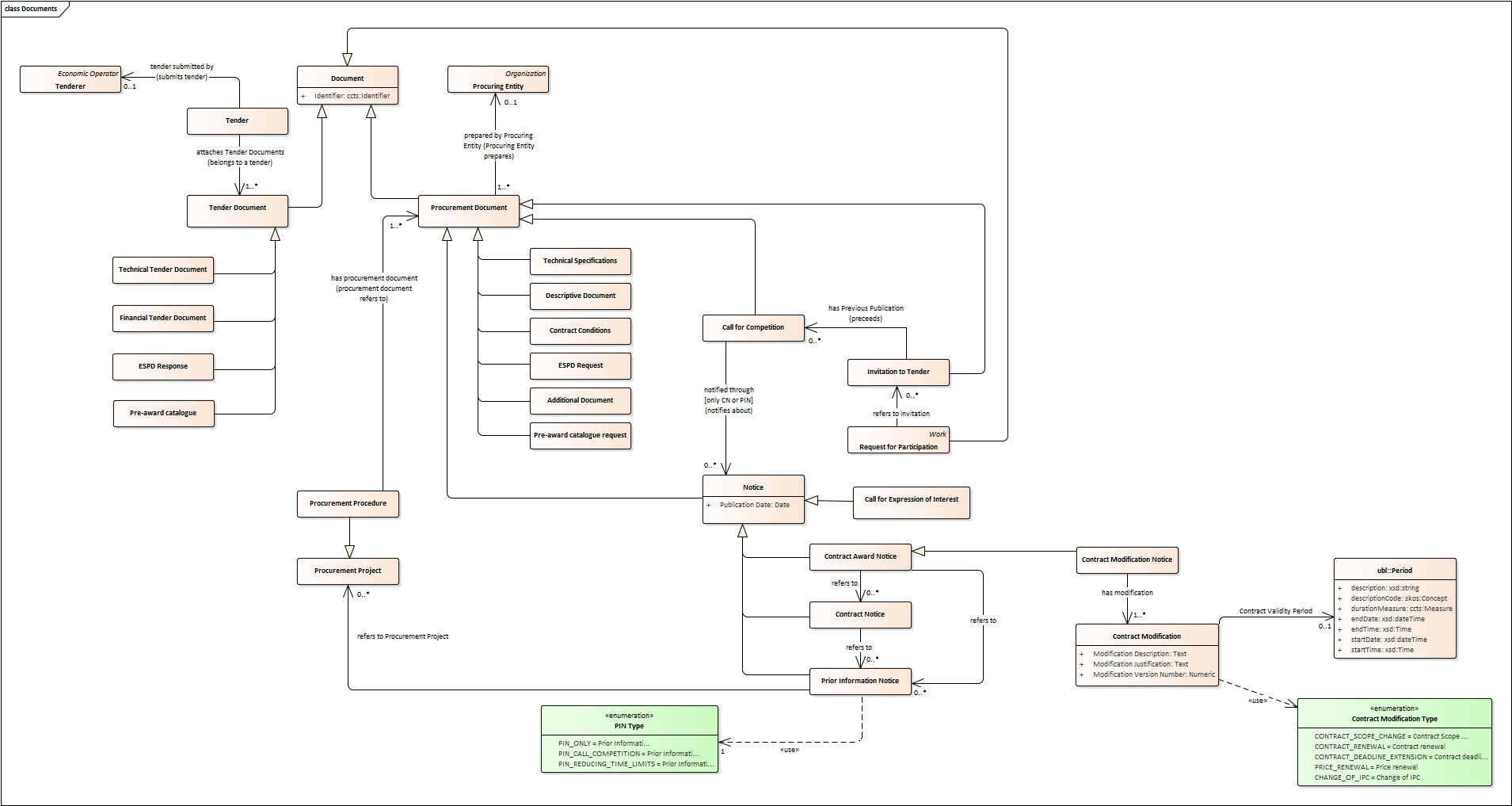
Documents
-
The ePO sees Documents as aggregators of the business domain data. In other words, the content of a Document are individuals that exist in the data graphs. A such (aggregators of individuals) they are ideal artifacts for the interoperability.
-
In the scope of the e-Notification and e-Access time, we can identify "Procurement Documents", whilst during the e-Submission, the Tenderer prepares and sends "Tender Documents".
-
Procurement Documents are prepared by the Procuring Entity and are always particular to a Procurement Procedure.
-
Several groups of Notices can be distinguished: Prior Information Notice, Contract Notice, Contract Award Notice and Call for Expression of Interest.
-
Prior Information Notices are often drafted prior to the existence of the Procurement Procedure and in some cases may refer to more than one Procurement Procedure.
-
Prior Information Notices (PIN) announce Procurement Projects.
-
Contract Notices (CN) announce the initiation of Procurement Procedures as do certain PINs. If the CN follows a PIN previously published, the CN should refer to that PIN.
-
Contract Award Notices (CAN) in turn announce the award of a Contract(s). In the case that a CN has been published prior to the CAN the CN should be referenced in the CAN. In the case where neither a PIN or CAN have been published prior to the CAN then a justification should be provided.
-
In restricted procedures the need of limiting the number of candidates to a short list may appear and for these cases Invitations to Tender are forward to each one of the candidates. Candidates interested in participating may submit a Request for Participation. The Invitation to Tender may refer to the Notices previously published in the context of the Procurement Procedure.
-
At tendering time, the Tenderer submits its own Tender Documents, which normally encompass a Financial Tender and a Technical Tender among other possible annexes and additional documents.
-
Contracts can experience minor modifications (Contract Modification), otherwise they may carry out new Procurement Procedures. Each modification has to be duly identified (see Contract Modification Type) and justified. These Modifications are to be published via Contract Modification Notices. Contract Modification notices are treated as Contract Award Notices.
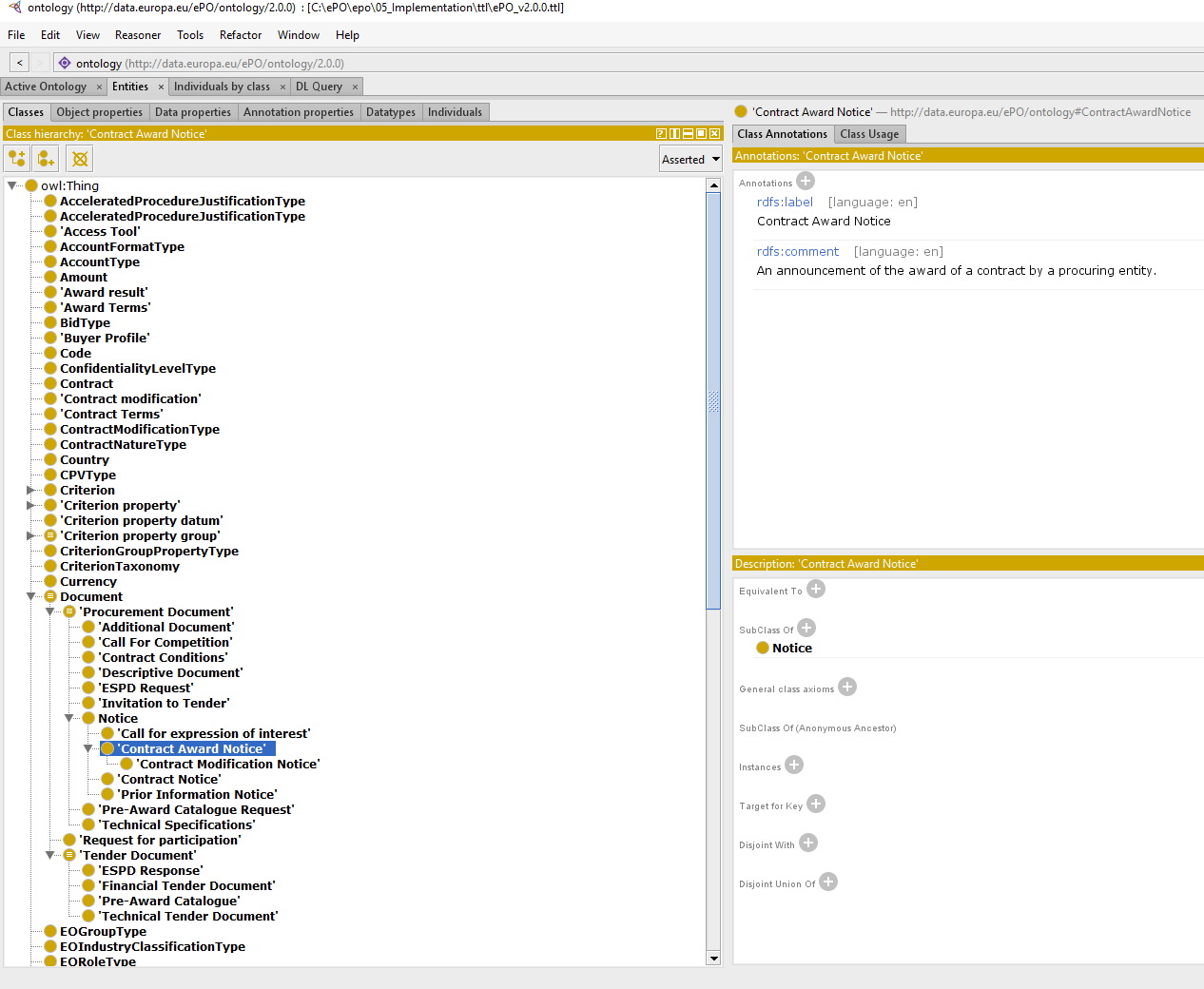
Contract Award Notice
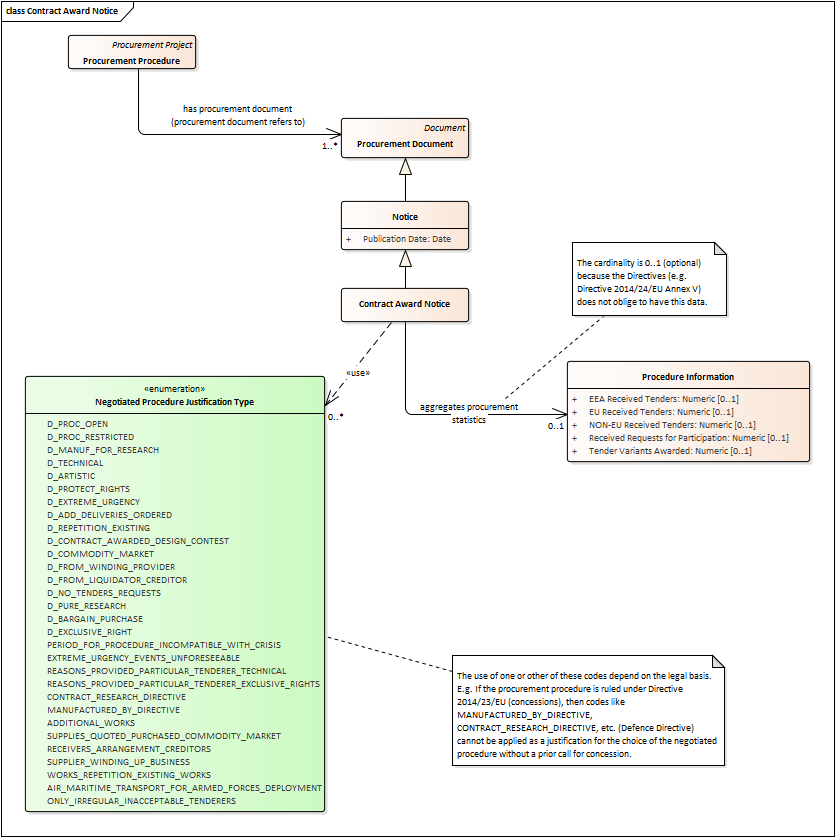
-
Procuring Entities shall publish the award of a contract by means of Contract Award Notices.
-
In the case of negotiated procedures without prior publication of a call for competition or for concession, a justification must be provided (Negotiated Procedure Justification Type)
Data Types
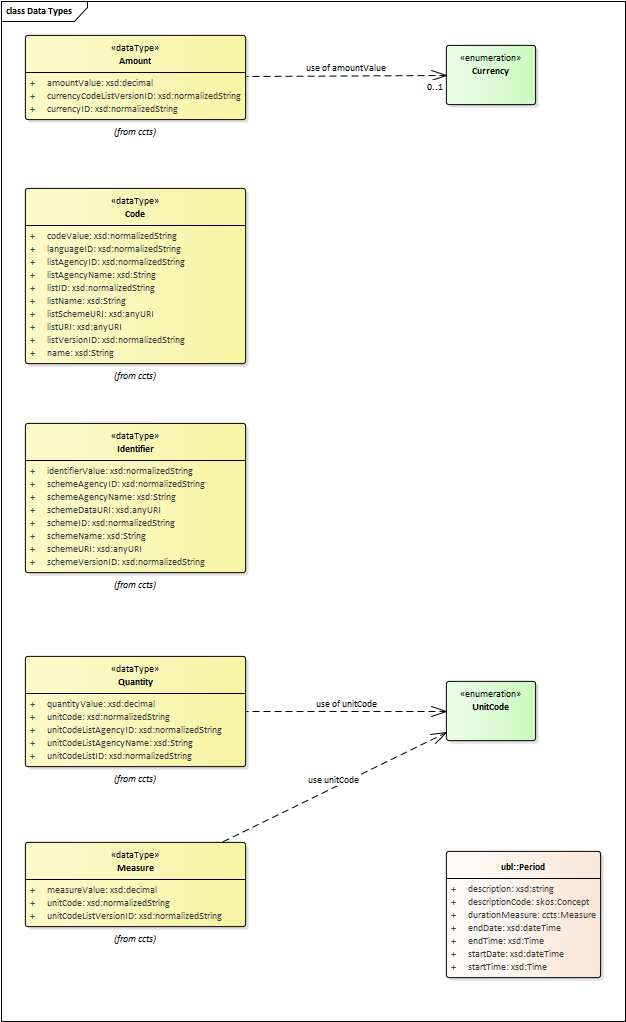
The Conceptual Data Model (CM) represents "data properties" (as understood from the ontology perspective) as "class attributes" (as normally represented in UML diagrams). For the representation of literals and other attributes, the CM uses the CCT notation (Text, Numeric, Indicator, Amount, etc.).
Beware, however that this ontology works with two types of data properties, those that can be considered truly "primitive" (like Text, Numeric, Indicator, Date) and those that have additional dimensions (attributes) like Identifier, Amount, Quantity, Measure and Code).
This ePO implementation "primitive" ones as xsd types, string for Text, dateTime for Date and Time, boolean for Indicator, decimal for Numeric, and so on. The rest of complex data types are implemented as classes with their own data properties, including a placeholder for the value (the actual datum). See section IV. Design and Implementation for details on the Turtle (TTL) implementation.
IV. Design and implementation
All deliverables produced in the previous tasks, e.g. Glossary and DED, but namely the Conceptual Data Model, were taken into account to produce an OWL ontology.
The outcome of this task are mainly the expression of the ontology T-Box as an OWL-DL Turtle syntax and a comparison of the tools used (Protégé 5.2 and VocBench 3.0) for the development of the T-Box.
This section describes the tasks performed during the design and implementation of the ontology (see process "OWL design and implementation" highlighted with a blue inverted "L" in the Knowledge Map below; inputs: "Conceptual Data Model v2.0.0", "OWL-Turtle syntax v2.0.0").
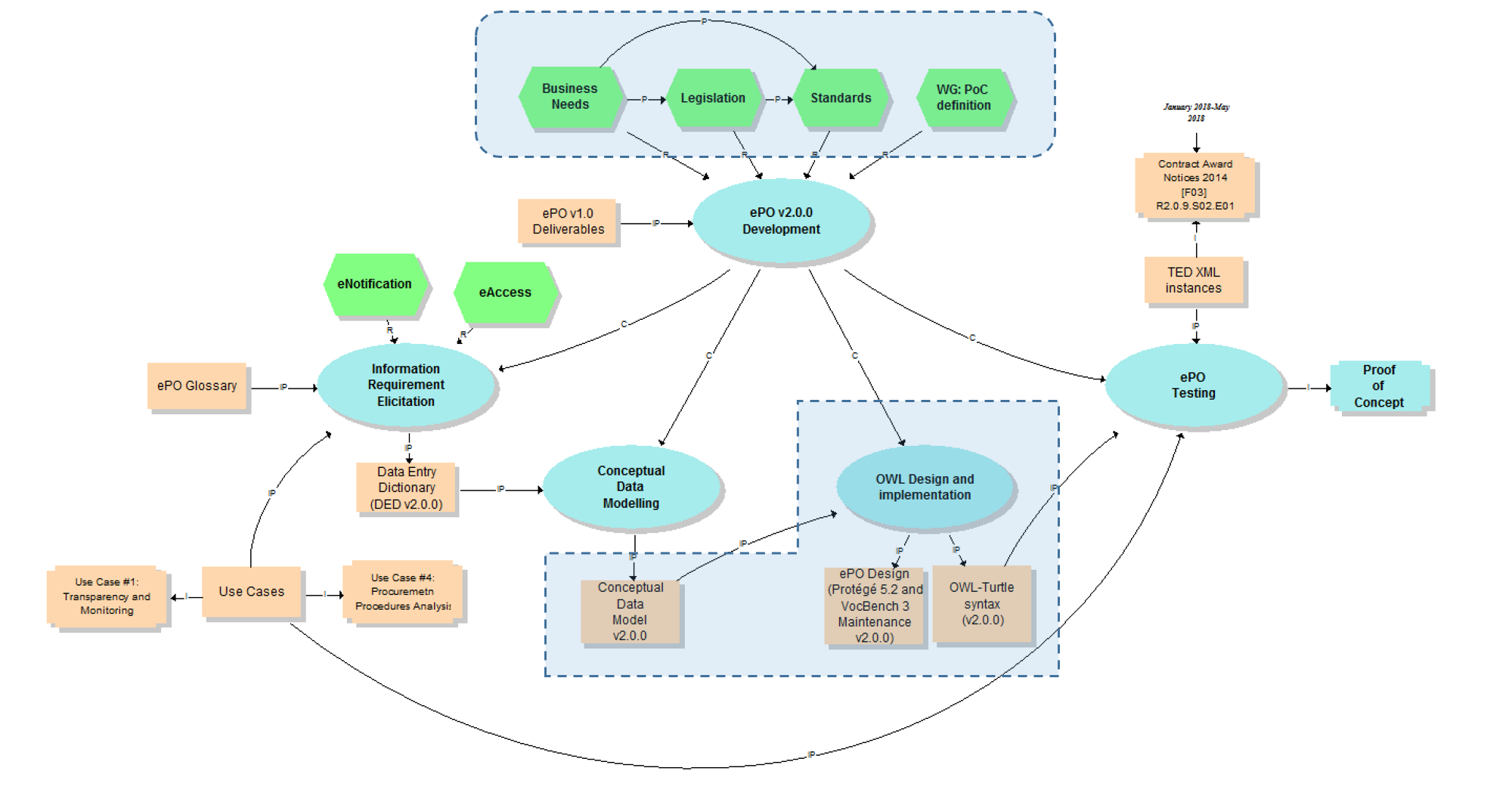
ePo 1.0 RDF-XML vocabulary
In ePO v1.0 the Working Group decided that the ontology was to be expressed as an RDF vocabulary. This vocabulary (without axioms defined therein) was expressed as an OWL-XML syntax: see file eproc_v0.6.owl located in the root folder of the GitHub code repository.
ePO v2.0.0 OWL-DL syntax
For this new version ePO v.2.0.0 the ePO development team proposed to the WG to approach the development of the ontology with the more expressive language OWL DL (Description Logic), which allows for advanced reasoning and logic inference, and the Turtle (TTL) syntax, as it is more human-readable than the OWL-XML equivalent.
|
Automated generation of the ePO-TTL T-Box
One way of automatising the generation of the OWL-TTL T-Box is to use the DED jointly with a transformation process and artefacts (e.g. XSL-T stylesheets for the conversion of the spreadsheet into TTL). This can be used for the generation of a first draft version that needs to be improved manually, e.g. using Protégé, VocBench or a simple txt editor. The production of such transformation and artefacts were out of the scope of this phase. |
As commented above, for the drafting of the TTL syntax the ePO development team used the Standford’s Protégé 5.2 editor. The resulting OWL-TTL file can be accessed from the GitHub Wiki page or from the repository.
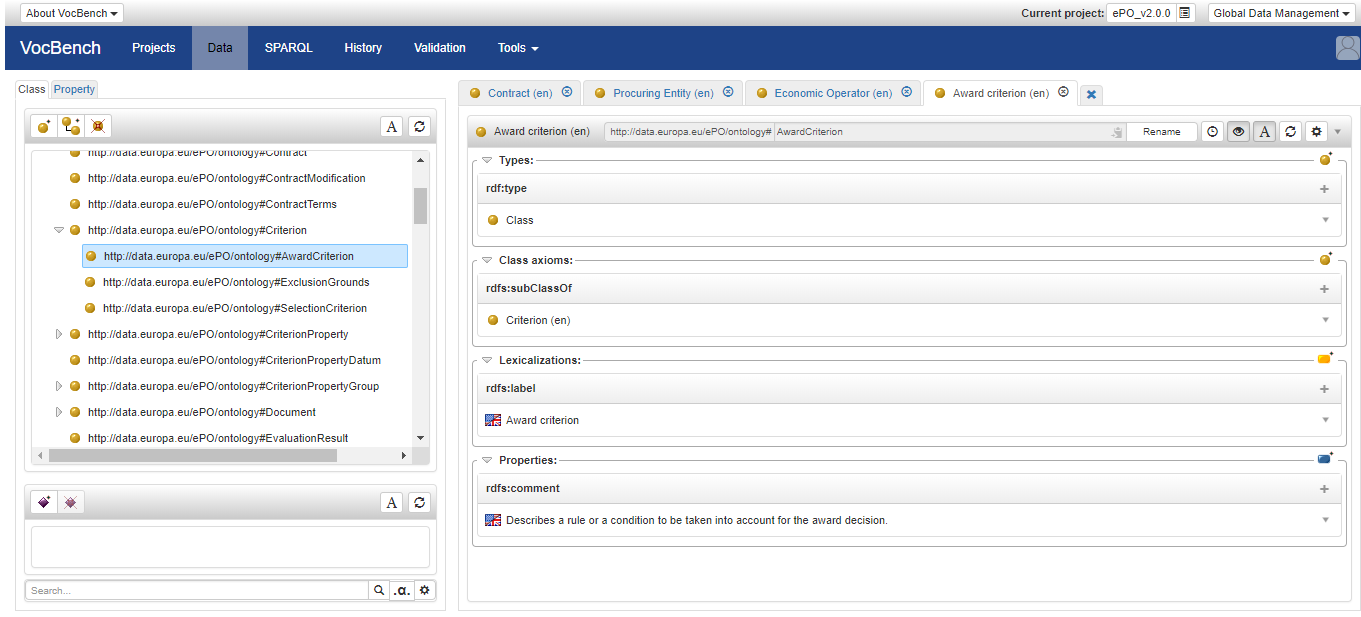
While developing and evolving the OWL-TTL each new version was also loaded and reviewed using the latest version of VocBench 3.0 (VB3). The objective of this exercise was to check the feasibility of using VB3 to maintain the ePO.
VocBench 3.0 is a free and open source platform for editing ontologies, thesauri and RDF datasets developed at University of Roma, Tor Vergata, under the mandate of the Publications Office of the European Union (OP).
Codes and Identifiers
A code is a shortened way (a number or a short abbreviated text), leading to the definition of a 'concept'. The code represents the concept and is used by software applications to retrieve the definition of the concept or make automatic decisions.
An Identifier, in turn, can be understood as a value (represented as a short text, a number or a combination of both) used to establish the identity of, and distinguish uniquely, one occurrence of an object following a pattern.
The essential distinctive features between identifiers and codes are:
-
Identifiers point at specific occurrences of objects (instances). Codes replace concepts, e.g. economic operator identifiers;
-
Identifiers are virtually limitless while codes are finite. In other words, identifier lists are “open” (the lists may grow) and code list are “quite closed” (they grow very slowly, once consolidated: new concepts appear rarely, and when an existing code needs to be modified a new code is added and the old one is marked as "deprecated", i.e. not to be used anymore at some point in time. Beware that "deprecation" doesn’t imply the elimination of the code from the code list, thus allowing for the coexistence of the deprecated code with new code(s) that replace it.
Hence codes are maintained in 'Code Lists' whilst identifiers are usually kept in databases.
-
Identifiers are in principle maintained in the business domain, e.g. procurement procedure identifiers, economic operator identifiers, product identifiers, etc.
Alignment to CCTS
The ePO tries to reuse as much as possible standards, specifications and practices commonly applied
in the eProcurement domain. Hence one design decision, coordinated with the WG members, was to
use the UN/CEFACT CCTS (Core Component Type Specification)
[7] to implement the data types Identifier, Amount, Quantity and Measure.
The package containing the OWL-TTL definition of these data type can be download from the ePO GitHub repository folder 05_Implementation/ttl/. Beware that codes are implemented as SKOS concepts (see also next section "Codes and code lists").
Codes and code lists
The ePO tries to reuse as much as possible the codes that are already used for e-Procurement. Many of these codes are already published in different formats by the Publications Office and are freely available in the section Authority Tables of the OP’s MDR site, which is being moved to their EU Vocabularies site.
These codes are described in "code lists", in all the EU official languages.
We distinguish at least three layers of codes:
-
Cross-sector, common, codes, like the ones defined and maintained by the ISO for currencies, languages, countries, etc.; or the ones defined by the European Commission that can be used in multiple business domains, e.g. the NUTS defined by EUROSTAT;
-
Business domain-related, maintained by international or European authorities, e.g. the ones defined by UNECE (as unit codes), or by the OP, e.g. types of procurement procedures (based on the EU Directives);
-
Project-specific (or application-specific), i.e. those codes that are particular of the project, e.g. codes used by the OP’s applications (eSenders' tools);
Codes are normally maintained in "code lists". In ePO the chosen syntax for the expression of codes is SKOS. The fragment of code below shows how an instance of a code is referred to in a SPARQL insert query:
PREFIX : <http://data.europa.eu/ePO/ontology#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
PREFIX org: <http://www.w3.org/ns/org#>
PREFIX vcard: <http://www.w3.org/2006/vcard/ns#>
PREFIX rov: <http://www.w3.org/ns/regorg#>
PREFIX adms: <http://www.w3.org/ns/adms#>
PREFIX ccts: <http://www.unece.org/cefact#>
PREFIX euvoc: <http://publications.europa.eu/ontology/euvoc#>
PREFIX epo-rd: <http://data.europa.eu/ePO/referencedata#>
INSERT
{
Graph <http://data.europa.eu/ePO/ontology> {
:PE143899-2018 rdf:type :ProcuringEntity ;
:usesProcuringEntityType epo-rd:CA ;
skos:prefLabel "Etat de Fribourg, Direction des finances, Service de l´informatique et des télécommunications (SITel)" ;
org:hasSite :PESite_143899-2018 ;
:usesJurisdictionalCompetenceLevelType epo-rd:AUTHORITY_LOCAL .
:PESite_143899-2018 rdf:type vcard:Individual ;
vcard:hasAddress :PEAddress143899-2018 .
:PEAddress143899-2018 rdf:type vcard:Address ;
vcard:region epo-rd:CH0 ; (1)
vcard:street-address "Route André Piller 50" ;
vcard:postal-code "1762" ;
vcard:country-name euvoc:CH ; (2)
vcard:hasEmail "AOP_SITel@fr.ch" ;
vcard:locality "Givisiez"
}
| 1 | NUTS 2016 code, defined by EUROSTAT |
| 2 | Country Code, available on the MDR |
This other code shows a fragment of the SKOS-AP-EU code list for countries. Click here to download the file.
<skos:Concept rdf:about="http://publications.europa.eu/resource/authority/country/LUX"
at:deprecated="false"
at:protocol.order="EU-16">
<rdf:type rdf:resource="http://publications.europa.eu/ontology/euvoc#Country"/>
<dc:identifier>LUX</dc:identifier>
<at:protocol-order>EU-16</at:protocol-order>
<at:authority-code>LUX</at:authority-code>
<at:op-code>LUX</at:op-code>
<atold:op-code>LUX</atold:op-code>
...
<skos:topConceptOf rdf:resource="http://publications.europa.eu/resource/authority/country"/>
<skos:inScheme rdf:resource="http://publications.europa.eu/resource/authority/country"/>
<owl:versionInfo>20180620-0</owl:versionInfo>
<dct:dateAccepted rdf:datatype="http://www.w3.org/2001/XMLSchema#date">2012-06-27</dct:dateAccepted>
<dct:created rdf:datatype="http://www.w3.org/2001/XMLSchema#date">2010-01-01</dct:created>
<dct:dateSubmitted rdf:datatype="http://www.w3.org/2001/XMLSchema#date">2011-10-06</dct:dateSubmitted>
<euvoc:startDate rdf:datatype="http://www.w3.org/2001/XMLSchema#date">1950-05-09</euvoc:startDate>
<euvoc:status rdf:resource="http://publications.europa.eu/resource/authority/concept-status/CURRENT"/>
<euvoc:order>EU-16</euvoc:order>
... etc.
One interesting aspect of the OP’s SKOS EU Application Profile (SKOS-AP-EU) is that all the metadata specified as
attributes of the ISO 15000 CodeType Core Component Specification are also expressed in the equivalent OP’s
SKOS-AP-EU code list. As a matter of fact, the features of the SKOS-XL specification which the SKOS-AP-EU
is built upon permits the specification of any metadata that can be necessary on both the code list (the "concept scheme")
and the individuals of the list (each "concept" of the list).
The figure below shows the set of attributes that can be used for a CCTS CodeType element:
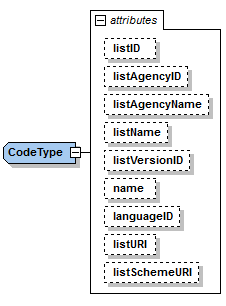
The table below contains the definitions of each attribute (as defined in OASIS UBL, ISO/IEC 19845:2015):
Attribute |
Definition |
listID |
The identification of a list of codes. |
listAgencyID |
An agency that maintains one or more lists of codes. |
listAgencyName |
The name of the agency that maintains the list of codes. |
listName |
The name of a list of codes. |
listVersionID |
The version of the list of codes. |
name |
The textual equivalent of the code content component. |
languageID |
The identifier of the language used in the code name. |
listURI |
The Uniform Resource Identifier that identifies where the code list is located. |
listSchemeURI |
The Uniform Resource Identifier that identifies where the code list scheme is located. |
Identifiers
As commented above, ePO defines a class Identifier in alignment to the UN/CEFACT Core Component Specification (CTTS). This Class looks like this:
@prefix : <http://www.unece.org/cefact#> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix xml: <http://www.w3.org/XML/1998/namespace> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix ccts: <http://www.unece.org/cefact#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix schema: <http://schema.org/> .
@prefix dcterms: <http://purl.org/dc/terms/> .
@base <http://www.unece.org/cefact> .
<http://www.unece.org/cefact> rdf:type owl:Ontology ;
owl:versionIRI <http://www.unece.org/cefact/2> ;
dcterms:title "Core Component Type Specification (CCTS)"@en ;
dcterms:creator [ schema:affiliation <https://www.unece.org/cefact/>
] ,
[ schema:affiliation [ foaf:homepage <http://www.everis.com> ;
foaf:name "Enric Staromiejski" ,
"Laia Bota" ,
"Maria Font"
]
] ;
rdfs:label "Core Component Type Specification (CCTS)"@en ;
dcterms:creator [ schema:affiliation [ foaf:homepage <https://publications.europa.eu/en> ;
foaf:name "The Publications Office of the European Union" ,
"Unit C2"
]
] ,
[ schema:affiliation <http://www.ebxml.org/>
] ;
dcterms:abstract "CCTS defines generic, business-agnostic, core components that are reused by other standards thus facilitating the interoperability at the technical level. Originally defined by ebXML, the specification is currently maintained by UN/CEFACT"@en .
#################################################################
# Data properties
#################################################################
### http://www.unece.org/cefact#identifierValue
ccts:identifierValue rdf:type owl:DatatypeProperty ,
owl:FunctionalProperty ;
rdfs:domain ccts:Identifier ;
rdfs:range xsd:normalizedString ;
rdfs:comment "The literal identifying an entity, like a person or an object."@en ;
rdfs:isDefinedBy <http://www.everis.com> .
### http://www.unece.org/cefact#schemeAgencyName
ccts:schemeAgencyName rdf:type owl:DatatypeProperty ,
owl:FunctionalProperty ;
rdfs:domain ccts:Identifier ;
rdfs:range xsd:string ;
rdfs:comment "The name of the agency that maintains the identification scheme."@en .
### http://www.unece.org/cefact#schemeDataURI
ccts:schemeDataURI rdf:type owl:DatatypeProperty ,
owl:FunctionalProperty ;
rdfs:domain ccts:Identifier ;
rdfs:range xsd:anyURI ;
rdfs:comment "The Uniform Resource Identifier that identifies where the identification scheme data is located."@en .
### http://www.unece.org/cefact#schemeID
ccts:schemeID rdf:type owl:DatatypeProperty ,
owl:FunctionalProperty ;
rdfs:domain ccts:Identifier ;
rdfs:range xsd:normalizedString ;
rdfs:comment "The identification of the identification scheme."@en .
### http://www.unece.org/cefact#schemeName
ccts:schemeName rdf:type owl:DatatypeProperty ,
owl:FunctionalProperty ;
rdfs:domain ccts:Identifier ;
rdfs:range xsd:string ;
rdfs:comment "The name of the identification scheme."@en .
### http://www.unece.org/cefact#schemeURI
ccts:schemeURI rdf:type owl:DatatypeProperty ,
owl:FunctionalProperty ;
rdfs:domain ccts:Identifier ;
rdfs:range xsd:anyURI ;
rdfs:comment "The Uniform Resource Identifier that identifies where the identification scheme is located."@en .
### http://www.unece.org/cefact#schemeVersionID
ccts:schemeVersionID rdf:type owl:DatatypeProperty ,
owl:FunctionalProperty ;
rdfs:domain ccts:Identifier ;
rdfs:range xsd:normalizedString ;
rdfs:comment "The version of the identification scheme."@en .
#################################################################
# Classes
#################################################################
### http://www.unece.org/cefact#Identifier
ccts:Identifier rdf:type owl:Class ;
rdfs:comment "A character string to identify and distinguish uniquely, one instance of an object in an identification scheme from all other objects in the same scheme together with relevant supplementary information. This class is based on the UN/CEFACT Identifier complex type defined in See Section 5.8 of Core Components Data Type Catalogue Version 3.1 (http://www.unece.org/fileadmin/DAM/cefact/codesfortrade/CCTS/CCTS-DTCatalogueVersion3p1.pdf). In RDF this is expressed using the following properties: - the content string should be provided using skos:notation, datatyped with the identifier scheme (inclduing the version number if appropriate); - use dcterms:creator to link to a class describing the agency that manages the identifier scheme or adms:schemaAgency to provide the name as a literal. Although not part of the ADMS conceptual model, it may be useful to provide further properties to the Identifier class such as dcterms:created to provide the date on which the identifier was issued."@en ;
rdfs:isDefinedBy <http://www.ebxml.org/> ,
<http://www.unece.org/cefact> ;
rdfs:label "Identifier"@en .
... etc.
This code matches the specification and definitions maintained by UN/CEFACT:

These definitions, as provided by OASIS UBL (ISO/IEC 19845), follow:
Attribute |
Definition |
schemeID |
The identification of the identification scheme. |
schemeName |
The name of the identification scheme. |
schemeAgencyID |
The identification of the agency that maintains the identification scheme. |
schemeAgencyName |
The name of the agency that maintains the identification scheme. |
schemeVersionID |
The version of the identification scheme. |
schemeDataURI |
The Uniform Resource Identifier that identifies where the identification scheme data is located. |
schemeURI |
The Uniform Resource Identifier that identifies where the identification scheme is located. |
V. Proof of Concept
The ePO development team agreed with the WG members to provide a means to test the deliverables produced, especially the Conceptual Data Model and the OWL-TTL implementation. With this purpose in mind a Proof of Concept was planned and executed.
This section describes the tasks performed during the development of the Proof of Concept (see process "ePO Testing" highlighted with a blue box; input: "TED XML instances", "OWL-Turtle syntax v2.0.0"; trace: "Proof of Concept").
The main objectives of the Proof of Concept were:
-
Test the coherence of the Conceptual Data Model (of the T-Box);
-
Test the consistency of the data once loaded (in the A-Box);
-
Test the effectiveness of the OWL implementation of the eProcurement Ontology (ePO); and
-
Test the feasibility of the ePO to support the Use Cases defined in ePO v.1.0.
Hence a varied set of activities were planned with these objectives in mind. The diagram below shows the activities that were planned and executed to develop the Proof of Concept:
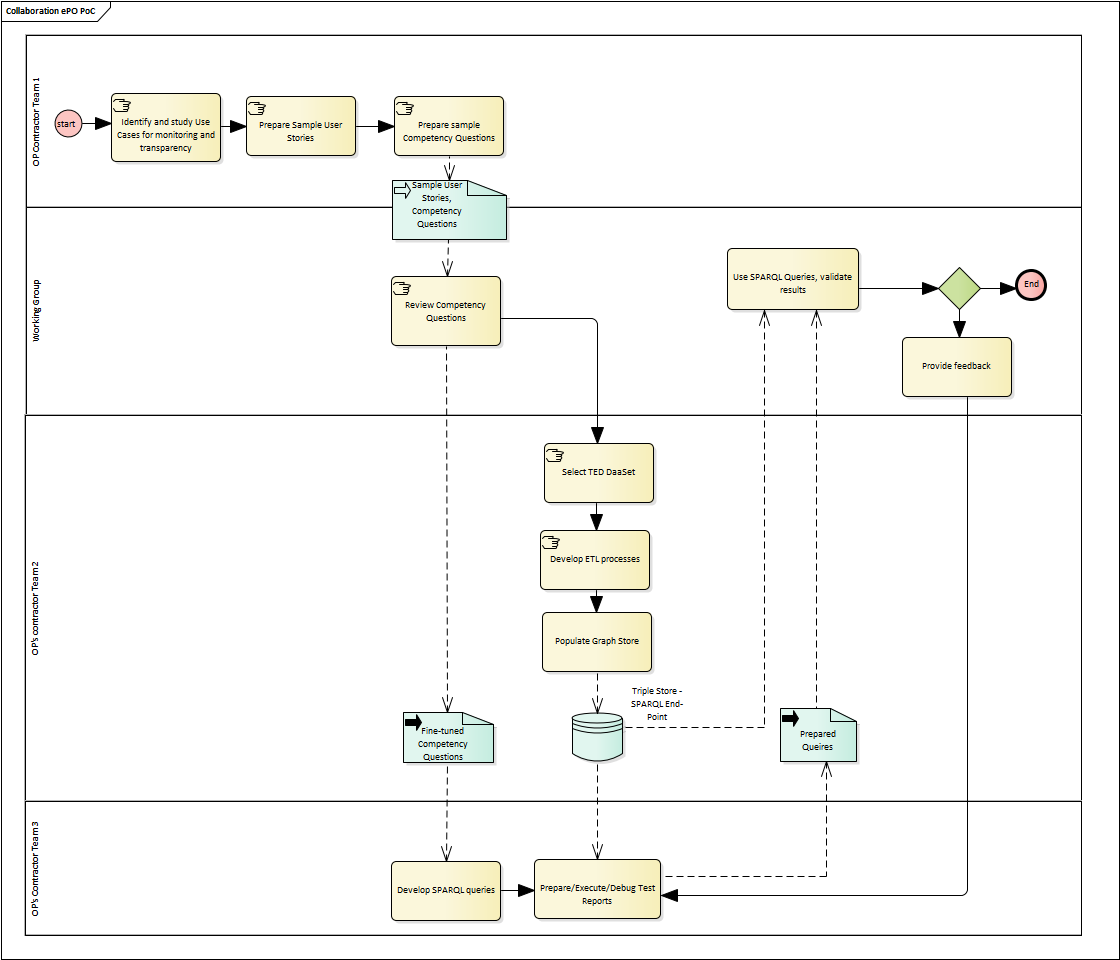
The following subsections explain how each of the activities mentioned in the diagram above has been developed and where to check the inputs, processes and results.
Activity 1: Use Cases
Activity name: |
Identify and study the Use Cases related to monitoring and transparency. |
Responsible team: |
OP’s contractor team. |
Inputs: |
ePO v1.0 Use Case 1 and Issue #11. |
Outputs: |
Study of the Use Cases (slightly renaming). |
The ePO v1.0 focused on three different Use Cases:
-
Use Case 1: Data Journalism
-
Use Case 2: Automated matchmaking of procured services and products with businesses, and
-
Use Case 3: Verifying VAT payments on intra-community service provision.
During its development a fourth Use Case was identified as relevant related to Transparency and Monitoring. This use case was proposed through an "Issue", in the GitHub repository. This Use Case was accepted as as a relevant case for transparency and monitoring.
Hence the ePO v2.0.0, which is focused only on transparency and monitoring, was developed taken into account two Use Cases (slightly renamed):
-
Use Case 1: Transparency and Monitoring; and
-
Use Case 4: Analyzing eProcurement procedures.
Activity 2: User Stories
Activity name: |
Prepare sample (example) User Stories. |
Responsible team: |
OP’s contractor team. |
Inputs: |
Use Cases 1 and 4. |
Outputs: |
Examples of User Stories. |
User Stories are a method of helping identify information requirements. The method consists in drafting very simple sentence structured around three main questions:
-
Who is the beneficiary of an action (who benefits from it)?
-
What is the need?
-
What is the benefit?
The structure of the sentence is always like this: “As a <role of the user>, I need <something>in order to <benefit>.”
Example:
As a contracting authority (ROLE), I need to know the number of tenderers (WHAT DO I NEED?) that have submitted a tender in order to add it to the award notice (BENEFIT).
Some examples of User Stories were prepared. The table below shows these sample User Stories for different roles and related to the Use Cases 1 and 4.

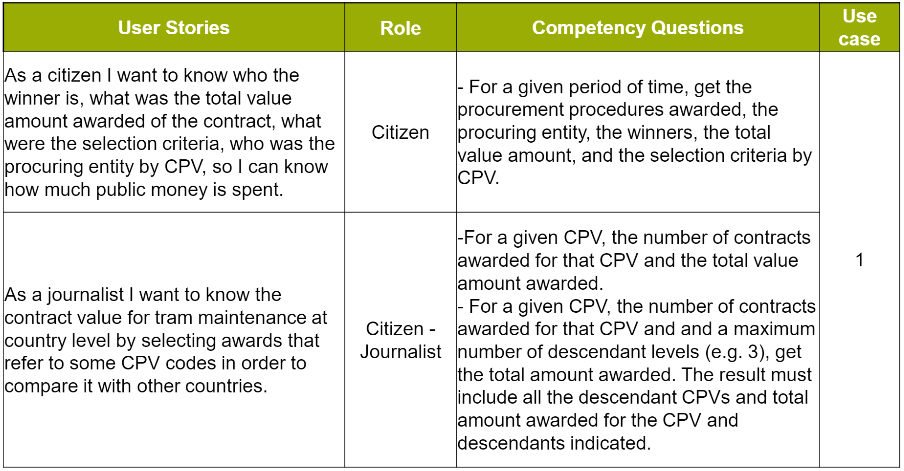
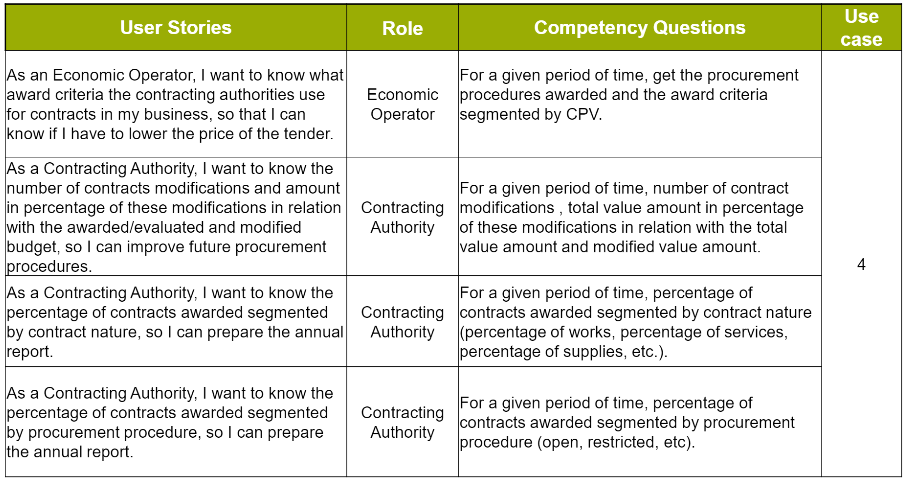
Activity 3: Competency Questions
Activity name: |
Prepare sample (example) Competency Questions. |
Responsible team: |
OP’s contractor team. |
Inputs: |
Use Cases 1 and 4, and the User Stories. |
Outputs: |
Examples of Competency Questions. |
User Stories help also draft very specific questions that need to be answered in order to meet the story. These questions will later on taken into account to draft concrete SPARQL queries.
Some examples of Competency Questions were prepared. The two tables below illustrate how these Competency Questions, linked to their respective User Stories, may look like. The link Competency Questions, in the GitHub Wiki page, supplies a longer list of concrete examples of CQ for the WG members to get inspiration.
Activity 4: Review CQs
Activity name: |
Review Competency Questions. |
Responsible team: |
Working Group members. |
Inputs: |
Competency Questions and related User Stories. |
Outputs: |
Comments by the WG members. |
The examples were made available to the Working Group members through the GitHub Wiki page. A special Add a new competency question to add comments or create new issues related to the CQs was also made available in the GitHub Wiki page.
Activity 5: Input Data Set
Activity name: |
Select Data Set. |
Responsible team: |
OP’s team. |
Inputs: |
Use Cases, User Stories, Competency Questions, agreement with the members of the WG. |
Outputs: |
Documents published on TED, accessed via the OP’s FTP server. |
For the extraction of data, the decision was made that the source of data should be the Contract Award Notices published on the TED website, as:
-
The Contract Award Notice (CAN) contains the data most relevant for Transparency, Monitoring and Procedure control (jointly with the Contract Notice (CN));
-
The CAN is the most published document, therefore the sample is richer;
-
The structure and elements of the standard form for the CAN are very similar or identical to many of other Notices. This allows to reuse a relevant part of the extraction and transformation artefacts (XSL-T) to process many other types of Forms.
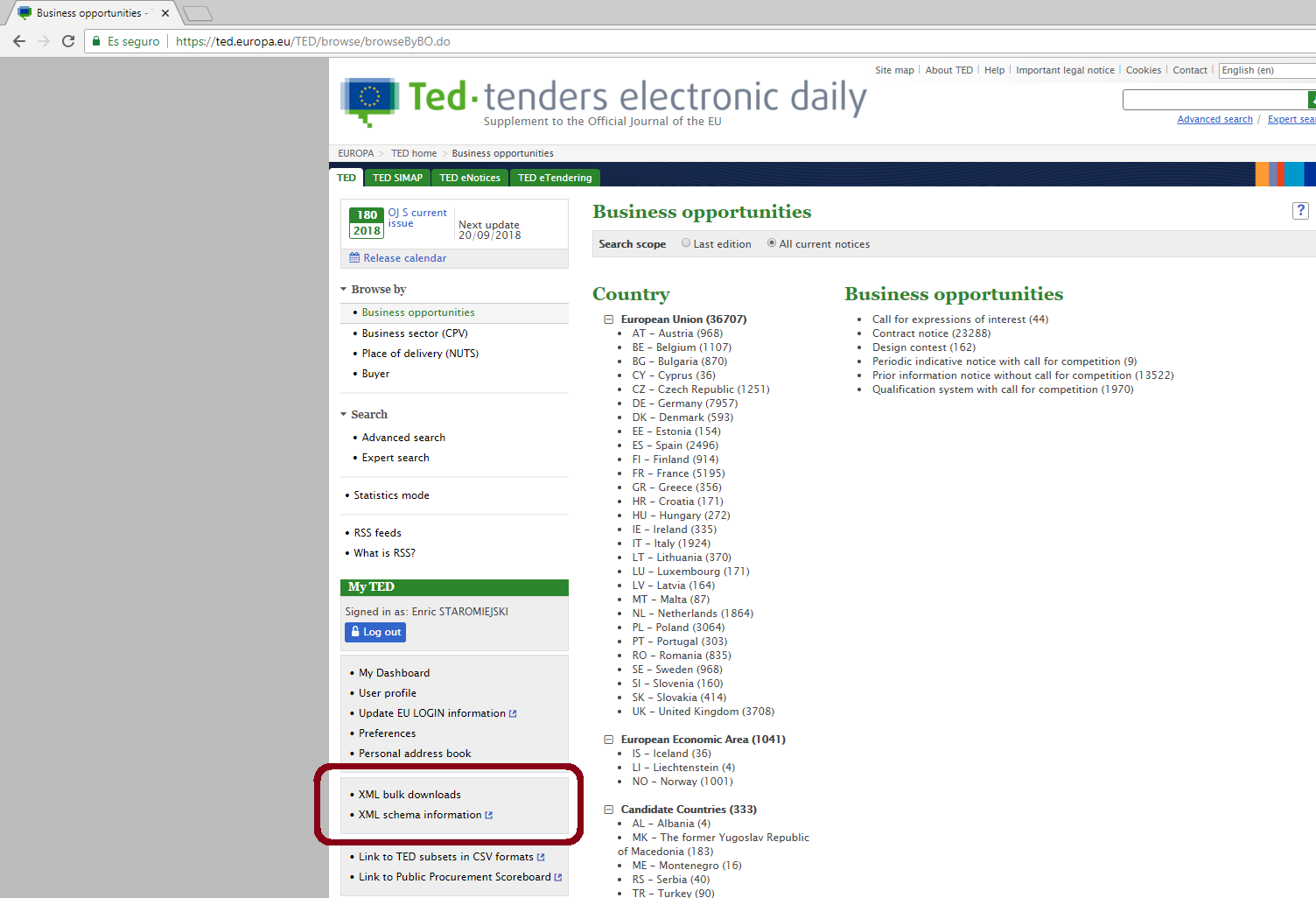
For bulk downloads of monthly or daily packages of XML TED offers two alternatives:
-
The menu “XML bulk downloads“ in “My TED”: to access this feature you will need to register as a User of the TED website and to have an ECAS account to authenticate yourself as a User of the EU Commission’s services;
-
The FTP server supplied by the OP at: ftp://ted.europa.eu/ (user: guest, password: guest). If you use this FTP Server note that there is a restriction on maximum number of connections to the ftp, with the following criteria:
-
Maximum number of overall connections: ~1050 but can be decreased to ~525 if the server is under maintenance;
-
Maximum 3 concurrent connections by IP or user;
-
A maximum of 100 concurrent connections for “legacy” user (i.e. not guest account) as same account could be used by several IPs. Once the limit is reached, the server will refuse new connections from the IP/user.
-
The TED-XML specification has been evolving for the past years. Different versions of XSD Schemas have been maintained in parallel. The result is that different schemas are being used to express the data in alignment to the 2014 Directives. For this PoC we decided to use the Contract Award Notice (CAN) form for Directive 2014 supporting the F03_2014.xsd standard form. Beware that notices in TED are in turn "enveloped" in another TED Schema, the R2.0.9.S01.E01 TED_EXPORT.xsd. All schemas are published on the Publications Office (OP) MDR site, which is being moved to to EU Vocabularies.
For this PoC we downloaded the *.tar.gz files corresponding
to January to May 2018. Bear in mind that, in the context of this PoC, we only extract data and import into the graph store the
CANs for Directive 2014. However the TED_EXPORT.xsd includes all the forms (F01 to F25) and the extraction process is able to extract data
from many of these forms, as they share a large part of the elements (see "Activity 6: ETL process", just below). If you want a go with these
other forms just uncomment the line "#DOCUMENT_TYPE_ID=1,2,3,22,23,24,25 " and comment the line "DOCUMENT_TYPE_ID=3" in the epo.properties file.
Activity 6: ETL process
Activity name: |
Develop ETL process. |
Responsible team: |
OP’s team. |
Inputs: |
TED-XML schemas (on MDR) and TED notices published on the TED FTP server. |
Outputs: |
TED to ePO Mapping (Wiring), Java code, XSL-T architecture, other resources (available on the GitHub repository and accessible via the GitHub Wiki page link Data Loading development (ETL). |
TED to ePO Mapping
ETL stands for Extraction, Transformation and Loading. The first step (Extraction) requires to identify well where the data of origin are and how they are expressed. For this, the ePO analysts produced a map putting side by side (wiring) each element of the TED-XML Schema (R2.0.9.S02.E01) and the corresponding element in ePO.
Technical approach
The ETL process was developed based on two technologies:
-
Java: version JDK 1.8 was used to build a Maven project (see pom.xml configuration file). The output of the build process is a "*.war" file. The source code is available on the GitHub code repository. This java code is responsible for (i) organising the TED-XML files; (ii) launching the extraction + transformation and/or the loading the data into the graph store, and (iii) log all the events and generate logs for monitoring the process;
-
XSL-T: version XSL-T 3.0 was used to draft a set of link: stylesheets the mission of which is to read the TED-XML files (Extraction) and transform that information into SPARQL INSERT patterns. Per each TED-XML a new TXT document is created with the mapped SPARQL INSERT patterns. The name of the resulting TXT takes the name of the TED XML file and appends the suffix "_output.txt". The piece of code below illustrates one of those examples (if you use the identifier of the document you should be able to find the TED-XML source in the TED Portal).
PREFIX : <http://data.europa.eu/ePO/ontology#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
PREFIX org: <http://www.w3.org/ns/org#>
PREFIX vcard: <http://www.w3.org/2006/vcard/ns#>
PREFIX rov: <http://www.w3.org/ns/regorg#>
PREFIX ccts: <http://www.unece.org/cefact#>
PREFIX euvoc: <http://publications.europa.eu/ontology/euvoc#>
PREFIX ubl: <http://docs.oasis-open.org/ubl#>
PREFIX epo-rd: <http://data.europa.eu/ePO/referencedata#>
INSERT DATA
{
Graph <http://data.europa.eu/ePO/ontology>{
:CAN_091271-2018 rdf:type :ContractAwardNotice ;
:hasPublicationDate "2018-03-01T00:00:00"^^xsd:dateTime ;
:hasDocumentIdentifier :CAN_ID_091271-2018
}
};
INSERT DATA
{
Graph <http://data.europa.eu/ePO/ontology>{
:CAN_ID_091271-2018 rdf:type ccts:Identifier ;
ccts:identifierValue "091271-2018" ;
ccts:schemeAgencyID "eu.europa.publicationsoffice.epo"
}
}
...
|
A note about the performance
The Java code developed and the XSL-T approach are extremely fast:
|
Code Execution
You can execute the code at least in two ways:
-
Either you clone the project onto your machine, import the Maven project in your preferred Java editor tool and execute the main class link: MainETLProcess.
-
Alternatively you may unzip the *.war file and execute the compiled code from a console window. The piece of code below provides a very simple script illustrating how this can be done:
#!/bin/bash
arg="$1"
exec java -classpath "lib/*:classes/." epo.MainETLProcess $argBeware that the MainETLProcess takes one argument:
Usage: epo.MainETLProcess [-t]|[-i]|[-a]
Valid arguments are:
-t .... transforms XML into .txt files containing the SPARQL queries, but does not execute the queries.
-i .... executes the SPARQL queries only.
-a .... does everything.
Options are mutually exclusive. Only one option is accepted.
Example:
java -classpath "lib/*:classes/." epo.MainETLProcess -t
java -classpath "lib/*:classes/." epo.MainETLProcess -i
java -classpath "lib/*:classes/." epo.MainETLProcess -aETL configuration
The java code uses a file named epo.properties. This file is to be located under the /home/user
directory of the computer from where the code is executed. See below an example of how this configuration
file looks like. Notice the two lines about the proxy configuration.
#Thu Jun 28 10:49:40 CEST 2018 ### Graph db access ############################################################################### #GRAPH_STORE_URL=http://34.249.1.15:7200 GRAPH_STORE_URL=http://localhost:7200 GRAPH_STORE_USER=paulakeen GRAPH_STORE_PASSWORD=shootingNicely2018Times GRAPH_STORE_REPOSITORY=ePO_test ### Proxy configuration ########################################################################## #PROXY_URL=10.110.8.42 #PROXY_PORT=8080 ### Directories configuration #################################################################### ## The directory where the TED-XML files are located INPUT_DATA_DIR=/TED-Resources ## The directory where the SPARQL INSERT TXT files, resulting form the XSL-T transformation, are written. ## This directory is the input directory from where the TXT files are taken to populate the Graph Store. OUTPUT_DATA_DIR=/TED-OUTPUT ## The directory where the java application logs the operations executed and execeptions. LOG_DATA_DIR=/TED-LOG ## Where the XSL-T architecture files are located. Relative or absolute paths can be specified. ## Relative paths are relative to the path from where the etl-process is launched. TED_TO_EPO_XSL=./src/main/resources/xslt/TEDXSD_to_ePOTTL.xsl ## Where the TED XSD Schemas are located. Relative or absolute paths can be specified. ## Relative paths are relative to the path from where the etl-process is launched. ## @DEPRECATED comment="the latest version uses STAX XMLStreamReader and works on multiple TED_XSD_VERSIONS TED_EXPORT_XSD=./src/main/resources/TED_publication_R2.0.9.S02.E01_003-20170123/TED_EXPORT.xsd ## Subystem IDs, XSD root element local name of the Subsystems that produced the XML instances that are ## requested to be processed. A comma separated list of names is expected. TED_SUBSYSTEMS=TED_EXPORT ## Version IDs of the TED-XSD schemas upon which the XML that are requested to be ## processed are instantiated. A comma separated list of names is expected. #TED_XSD_VERSIONS=R2.0.9.S02.E01, R2.0.9.S01.E01 TED_XSD_VERSIONS=R2.0.9.S02.E01 ## Form types requested to be processed. #TED_XSD_FORM_TYPES=F01, F02, F03 TED_XSD_FORM_TYPES=F03
| Notice that each execution of the ETL process generates a log file in the specified directory (property "LOG_DATA_DIR"). The log files append the total number of files transformed and inserted at the end of the file. These figures can be used to study the amount and types of documents that have been published by the OP. For an example see the section following Activity 7: Populate Graph store. The data were extracted from the logs about the transformation of each month of 2018, separately, from January to May. |
Activity 7: Populate Graph store
Activity name: |
Populate the Graph store. |
Responsible team: |
OP’s team. |
Inputs: |
The result of the XSL-T-based transformation (SPARQL INSERT queries). |
Outputs: |
The Graph store is populated with triples. |
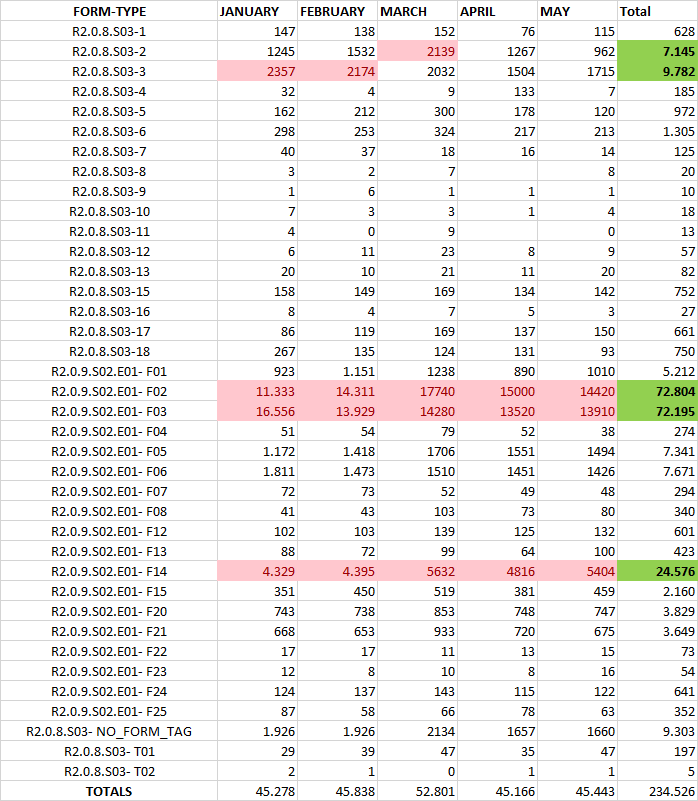
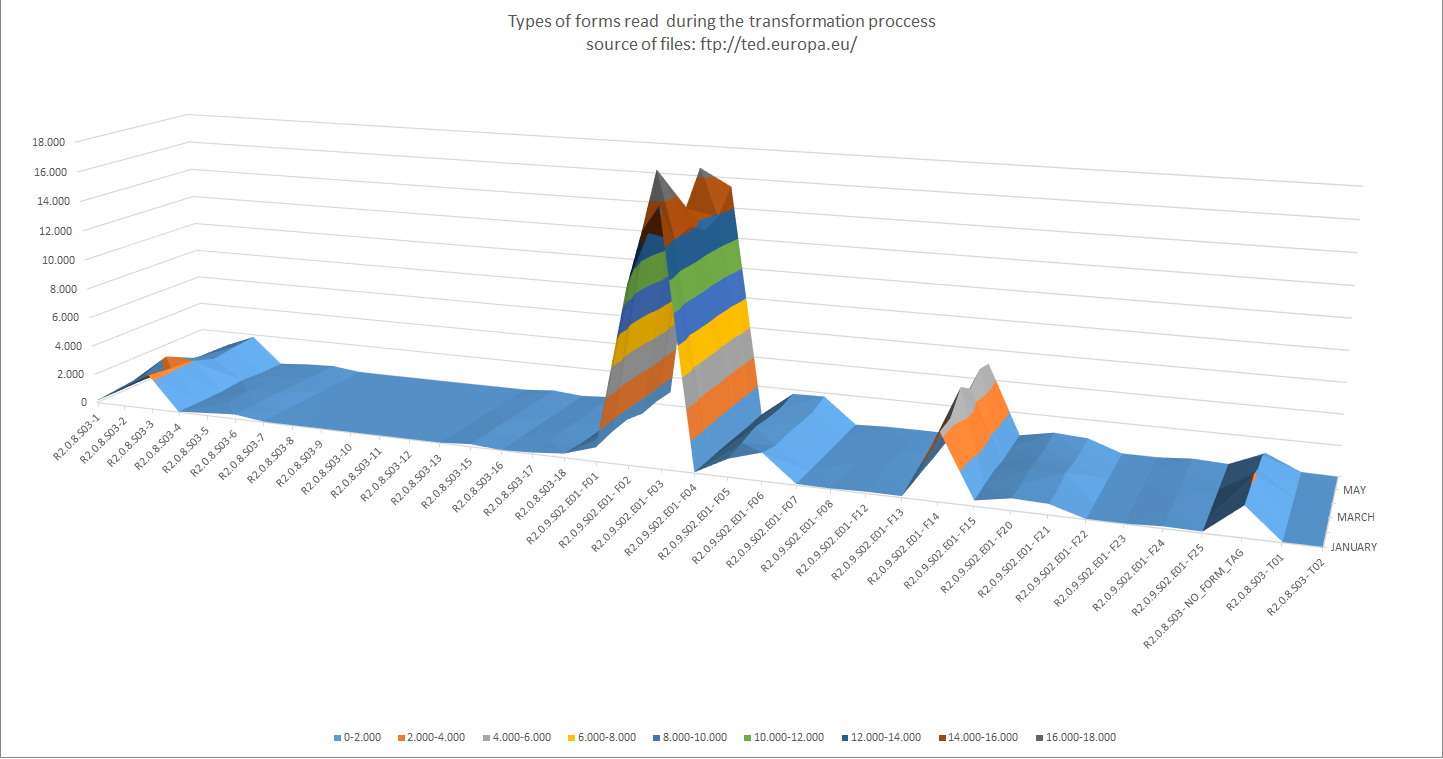
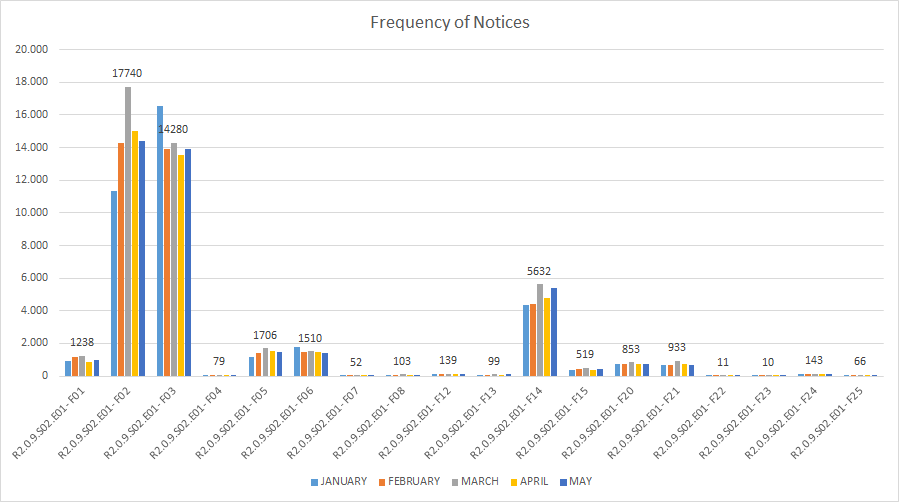
A large amount of TXT files containing the SPARQL INSERT queries was automatically obtained - out of the transformation- for the five first months of 2018. The table and bar graphic below show the exact number of files processed and the number of Contract Award Notices imported into the Graph Store.
| Please beware that the files indicated in the figure below refer to the files that were "downloaded and read" (processed) from the FTP Server and that only CANs based on the Directive 2014/24/EU were actually imported into the GraphDB Store. |
The Graph Store chosen for this PoC was the Community version of GraphDB (version 8.5) which can be freely downloaded from the Ontotext website.
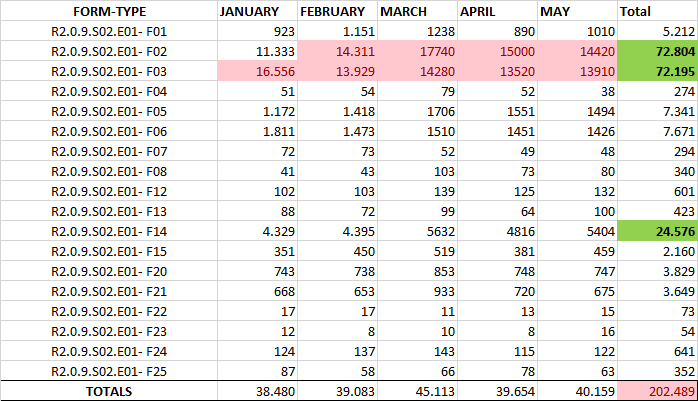
"The graph below, generated out of the figures in the table above, supports the statement that the data in Contract Award Notices are amongst the most abundant (and are relevant)."
Activity 8: SPARQL Queries
Activity name: |
Develop SPARQL Queries. |
Responsible team: |
OP’s team |
Inputs: |
Competency Questions. |
Outputs: |
The Graph store is populated with triples. |
The document SPARQL Query examples provides a few examples that were provided for the Working Group (WG) members to have a glimpse at how efficiently the ePO is responding.
Query examples
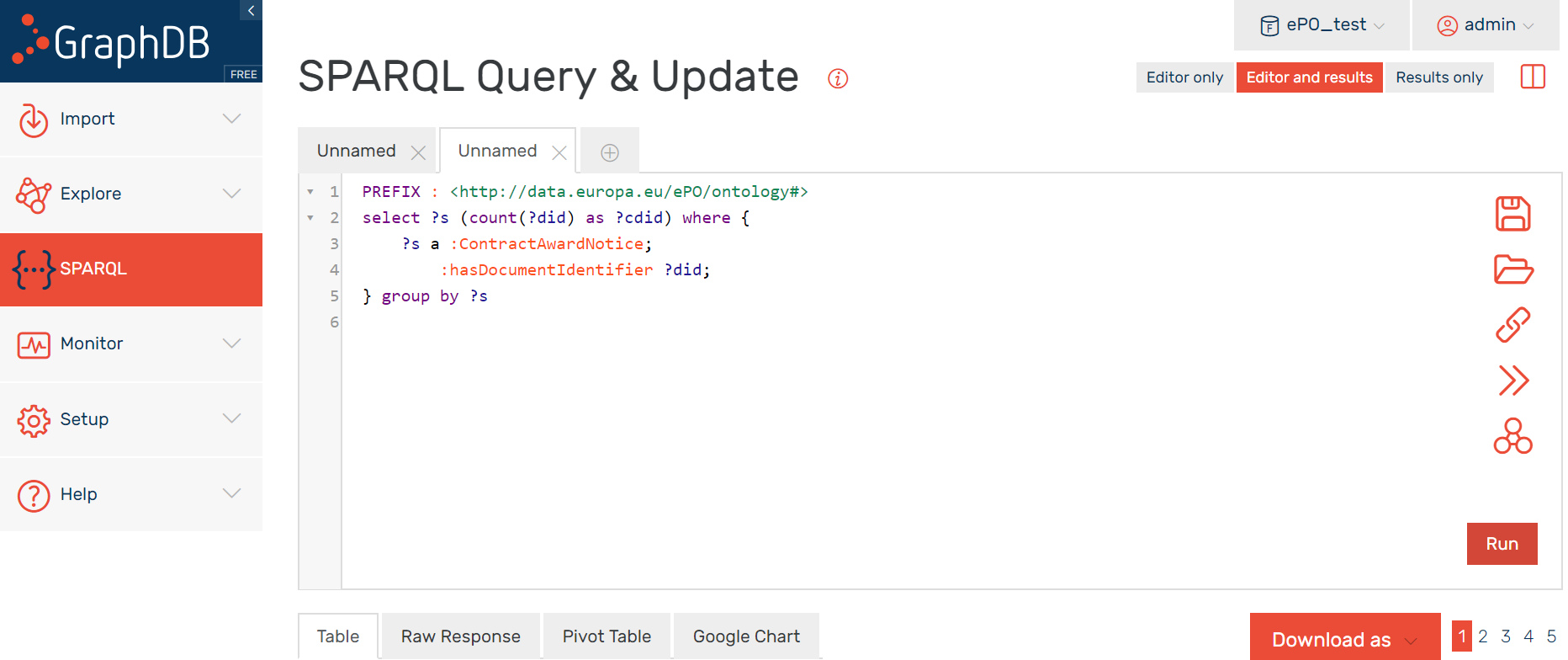
Example 1: One very first exercise would consist in checking the amount of Contract Award Notice and to compare it to the number of transformations executed and compiled in the log files. For this open a browser, introduce the URL or IP of the GraphDB server (e.g. 34.249.1.15:7200) and copy this SPARQL Query in the textfield of the SPARQL Endpoint:
PREFIX : <http://data.europa.eu/ePO/ontology#>
select ?s (count(?did) as ?cdid) where {
?s a :ContractAwardNotice;
:hasDocumentIdentifier ?did;
} group by ?s
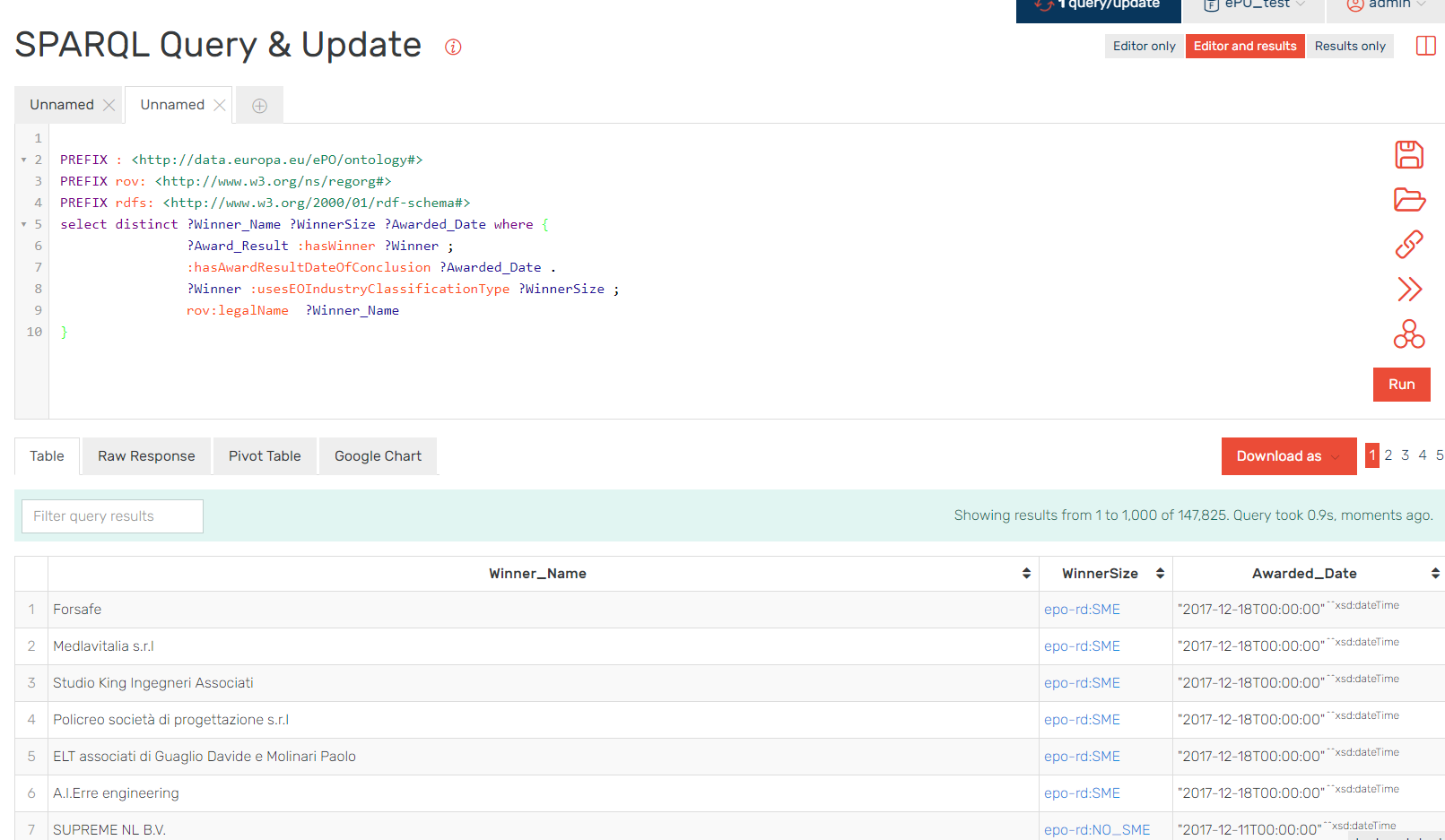
Example 2: List all the winners, the size of the company and the date of award.
PREFIX : <http://data.europa.eu/ePO/ontology#>
PREFIX rov: <http://www.w3.org/ns/regorg#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
select distinct ?Winner_Name ?WinnerSize ?Awarded_Date where {
?Award_Result :hasWinner ?Winner ;
:hasAwardResultDateOfConclusion ?Awarded_Date .
?Winner :usesEOIndustryClassificationType ?WinnerSize ;
rov:legalName ?Winner_Name
}
Example 3: Number of contracts awarded for each CPV (beware that one Contract Award Notice may refer to multiple contracts).
PREFIX : <http://data.europa.eu/ePO/ontology#>
SELECT ?cpv (COUNT(DISTINCT(?contract)) AS ?number_contracts) where {
?contract a :Contract;
:hasContractPurpose ?purpose.
?purpose :hasCPVType ?cpv.
} group by ?cpv order by desc(?number_contracts)
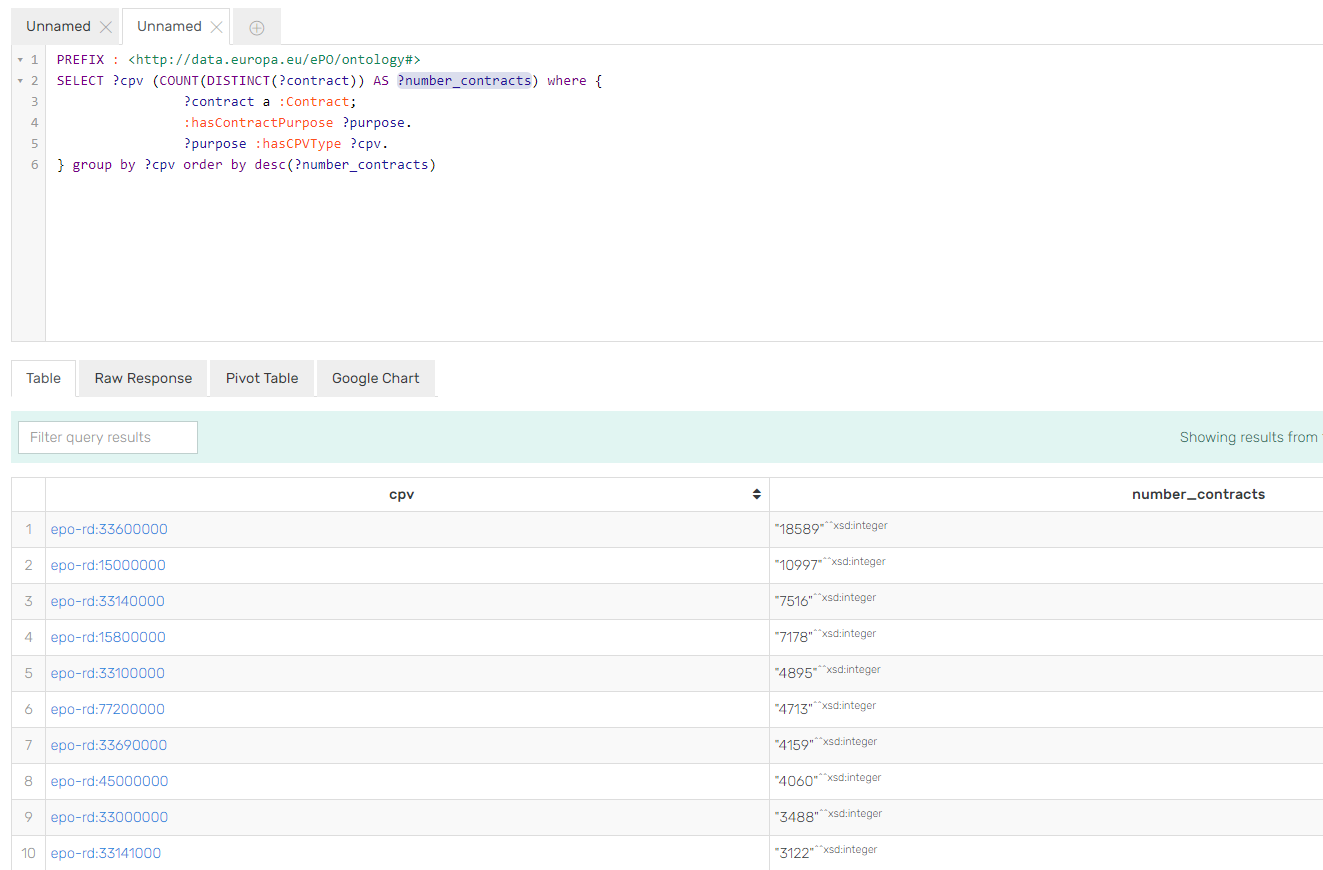
See the document SPARQL Query examples for more contextualisation and examples.
Activity 9: Test and debug
Activity name: |
Prepare/Execute/Debug Test Reports |
Responsible team: |
WG Members supprted by the OP development team. |
Inputs: |
Ad-hoc SPARQL queries prepared on the basis of Transparency, Monitoring and Procurement Procedure management perspectives. |
Outputs: |
SPARQL table results and graphic representations. |
Additional revision, testing an debugging is currently being performed on the Conceptual Data Model and the OWL TTL. This task is being done jointly with the OP officers, the WG members and the ePO development team.
Anyone interested in participating in this task of improvement is welcome to join.
One suggestion for the WG members, or anyone interested in transparency, competition, monitoring, etc. would be that they try to obtain KPIs (Key Performance Indicators) as the ones shown in the EU Single Market on Public Procurement.
Next we show one example for the first one, KPI I: Single bidder. The source of information for the results shown are the Contract Award Notices (CAN) extracted from the OP’s TED ftp server. The sample covers only CANs under Directive 2014/24/EU, from January to May 2018).
While comparing results to the ones presented on the EU Single Market portal, bear in mind that the information used by that portal is also extracted from the TED, but their sample is much bigger and richer (more years, types of forms and different releases) than the one used for this PoC.
The explanations about "What they do measure, what they do reflect, and how to interpret the results" were copied as-they-are in the EU Single Market portal.
Indicator I: Single bidder
What does it measure? |
The proportion of contracts awarded where there was just a single bidder (excluding framework agreements, as they have different reporting patterns). |
What does it reflect? |
Several aspects of procurement, including competition and bureaucracy. |
How to interpret it? |
More bidders are better, as this means public buyers have more options, and can get better value for money. |
PREFIX : <http://data.europa.eu/ePO/ontology#>
PREFIX rov: <http://www.w3.org/ns/regorg#>
PREFIX org: <http://www.w3.org/ns/org#>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX vcard: <http://www.w3.org/2006/vcard/ns#>
select distinct ?c (concat(str(round(?cc * 100 / ?countContract)), '%') as ?percent) where
{
{select ?c (count(?c) as ?cc) where {
{select ?ar (count(?w) as ?cw) where{
?contract a :Contract ;
:refersToAwardResult ?ar.
?ar :hasWinner ?w
filter not exists {?contract :hasFrameworkContract ?fc}
} group by ?ar
having (count(?w) = 1)}
?ar :hasWinner ?w .
?w org:hasSite ?s .
?s vcard:hasAddress ?a .
?a vcard:country-name ?c} group by ?c order by ?c
}
{
select ?c (count(?c) as ?countContract) where
{
?con a :Contract ;
:refersToAwardResult ?ar .
?ar :hasWinner ?w .
?w org:hasSite ?s .
?s vcard:hasAddress ?add .
?add vcard:country-name ?c
} group by ?c order by ?c
}
}
|
KPI I. Result-set (csv)
Click here to download the figures resulting from the query:
Query Result
|
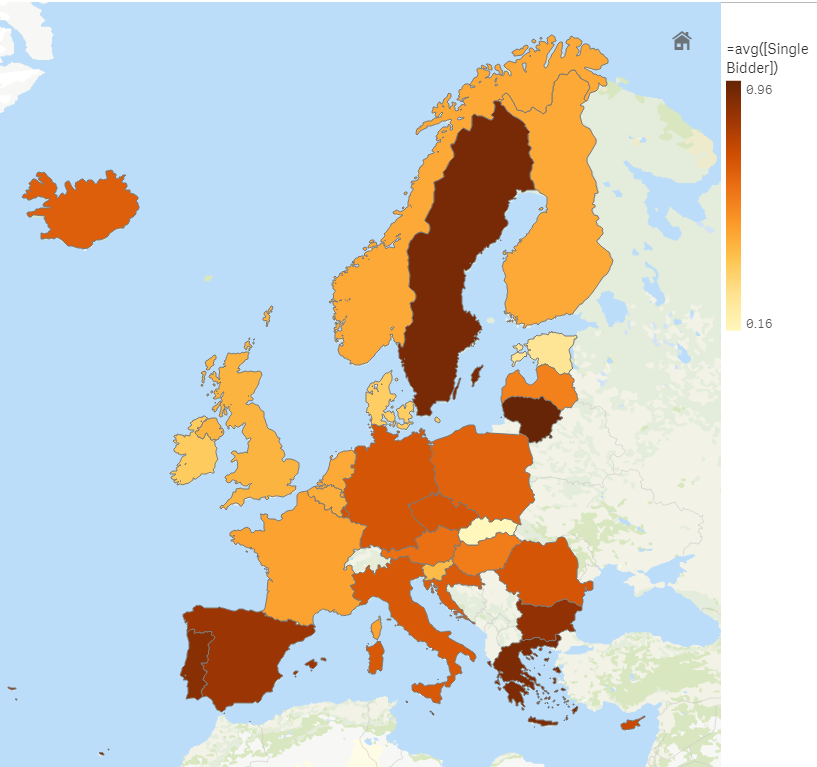
Activity 10: Validate results
Activity name: |
Use SPARQL queries, validate results. |
Responsible team: |
Working Group WG members. |
Inputs: |
Example SPARQL queries supplied by the OP’s team. |
Outputs: |
SPARQL result-tables. |
The members of the Working Group are expected to study this documentation and the rest of deliverables, signal possible errors and improvements and issue their opinion, recommendations, additional examples and comments.
With all the materials developed, namely the Conceptual Data Model, the OWL-TLL ontoly, SPARQL query examples and the documentation produced for this phase, the members of the Working Group have sufficient elements to define their own Test Cases, prepare the necessary SPARQL queries and execute them by themselves using the SPARQL endpoint that OP made publicly available.
If prompted for a user sign in, use "guest" for both, the user name and the password.
Activity 11: Provide feedback
Activity name: |
Provide feedback |
Responsible team: |
Working Group WG) members. |
Inputs: |
OP’s example queries and WG’s own Competency Questions and queries |
Outputs: |
Feed-back via the link: GitHub Issues work-space. |
OP development team will suport the WG members in case of doubts or issues related to the development or the SPARQL endpoint.
Any issue related to the design or implementation of the ePO is expected to be raised in the GitHub Issues workspace.
Annex I: Types of documents processed
During the development of the ETL process a certain effort was invested in analsying which documents are published on TED, in which quantities, the variations month to month, etc.
It was interesting to confirm that the information already advanced by the OP for previous years is consistent with the figures[8] obtained for the first months of 2018 (January to May), during the ETL Transformation phase, e.g.:
-
The most published documents are Contract Notices (F02) and Contract Award Notices (F03);
-
The amount of one type of notice published is very regular (similar) all along the year;
-
The average of documents published monthly is quite regular (around 45,000);
-
Many eSenders are still using the old version R2.0.8 schema, especially for CN and CAN (over 10% of the total in January and February, but it is a descending trend)
-
Corrigenda (F14) are intensively used (around 10% of the documents published are corrigenda).